SE::DuckDuckGo::Position - Vérification des positions d'un site par mots-clés dans DuckDuckGo
Présentation du scraper
Scraper de vérification des positions d'un site par mots-clés dans DuckDuckGo. Grâce au scraper SE::DuckDuckGo::Position, vous pourrez vérifier automatiquement les positions dans les résultats de DuckDuckGo en utilisant vos propres bases de domaines. L'utilisation du scraper SE::DuckDuckGo::Position permet de déterminer facilement, précisément et rapidement la position d'un site dans DuckDuckGo.
Les fonctionnalités d'A-Parser permettent de sauvegarder les paramètres de collecte de données du scraper SE::DuckDuckGo::Position pour une utilisation ultérieure (gabarits), de définir un calendrier de collecte et bien plus encore. Vous pouvez utiliser la substitution automatique de sous-requêtes à partir de fichiers.
La sauvegarde des résultats est possible dans la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarits intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'afficher les données dans divers formats, y compris JSON, SQL et CSV.
Données collectées
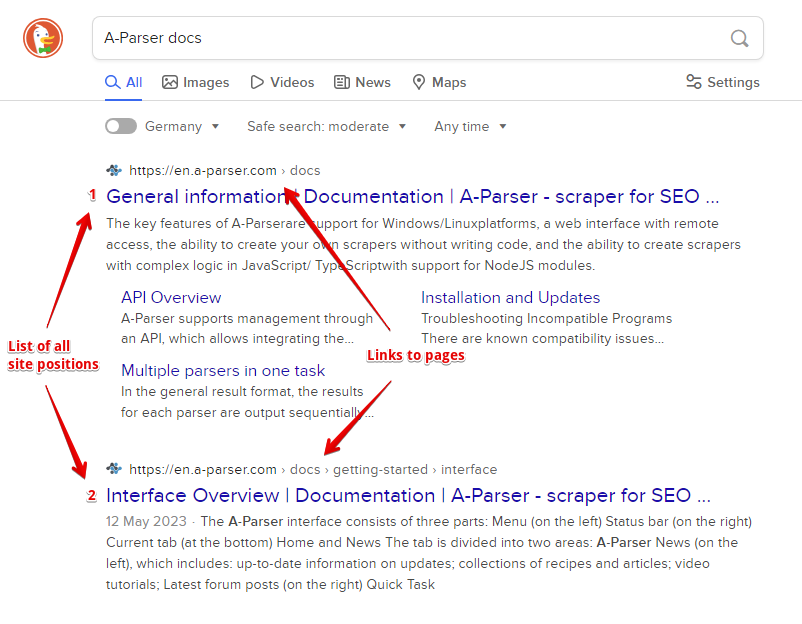
- La position du site et le lien vers la page du site
- La liste de toutes les positions du site et des liens vers les pages
Fonctionnalités
- Toutes les fonctionnalités du scraper
 SE::DuckDuckGo
SE::DuckDuckGo - Arrête automatiquement la collecte de données lorsqu'un site est trouvé
- Prend en charge la recherche de sous-domaines
- Possibilité de comparer la position recherchée par domaine, par domaine principal et par lien complet
- Collecte des positions pour plusieurs domaines à la fois
Cas d'utilisation
- Vérification des positions de ses propres sites et de ceux des concurrents
- Recherche de pages générant du trafic sur un site
Requêtes
Comme requêtes, il est nécessaire d'indiquer le domaine du site recherché et la requête de recherche séparés par un espace, par exemple :
lenta.ru actualités
lenta.ru actualités en ligne
ria.ru actualités
a-parser.com A-Parser
S'il est nécessaire de vérifier un seul site par rapport à une liste de requêtes, vous pouvez indiquer le domaine dans le format de requête (Query format) :
lenta.ru $query
Ou utiliser simplement une liste de mots-clés. Pour utiliser plusieurs domaines à la fois dans une requête, vous devez indiquer la liste des domaines séparés par des virgules, puis un espace et le mot-clé, par exemple :
lenta.ru,ria.ru,notfound.com actualités flux
Les résultats seront enregistrés dans le tableau $bulkcheck.
L'option Stop when found est également prise en charge, la collecte s'arrêtera si des positions ont été trouvées pour tous les domaines.
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour la substitution automatique de sous-requêtes à partir de fichiers. Par exemple, si nous voulons vérifier des sites/un site par rapport à une base de clés, indiquons quelques requêtes principales :
ria.ru
lenta.ru
rbc.ru
yandex.ru
Dans le format de requêtes, indiquons la macro de substitution de mots supplémentaires à partir du fichier Keywords.txt. Cette méthode permet de vérifier une base de sites par rapport à une base de clés et d'obtenir les positions en résultat :
$query {subs:Keywords}
Cette macro créera autant de requêtes supplémentaires qu'il y en a dans le fichier pour chaque requête de recherche initiale, ce qui donnera au total [nombre de requêtes initiales (domaines)] x [nombre de requêtes dans le fichier Keywords] = [nombre total de requêtes] suite au travail de la macro.
Variantes d'affichage des résultats
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarits intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme arbitraire, ainsi que structurée, par exemple CSV ou JSON.
Exportation de la liste des positions
Obtention du résultat sous la forme :
domaine recherché - clé : numéro de position dans les résultats
Format du résultat :
$domain - $key: $position\n
Exemple de résultat :
lenta.ru - actualités en ligne: 13
lenta.ru - actualités: 26
ria.ru - actualités: 1
a-parser.com - A-Parser: 1
...
Vérification simultanée de plusieurs domaines (vérification par lot)
Les informations sur tous les domaines lors d'une vérification simultanée de plusieurs domaines sont contenues dans le tableau $bulkcheck.
Format du résultat :
$bulkcheck.format('$domain - $position\n')
Exemple de requête :
lenta.ru,ria.ru,notfound.com actualités flux
Exemple de résultat :
lenta.ru - 2
ria.ru - 6
notfound.com - 0
Liens + ancres + snippets avec affichage de la position
Affichage des liens, ancres et snippets dans un tableau CSV
Sauvegarde des mots-clés associés
Concurrence des mots-clés
Vérification de l'indexation des liens
Sauvegarde au format SQL
Dump des résultats en JSON
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte de données. Dans cette section, nous avons listé les cas les plus populaires pour le scraper SE::DuckDuckGo::Position.
Sauvegarde des domaines sans positions nulles
L'exemple de vérification simultanée de plusieurs domaines (voir plus haut dans les variantes d'affichage des résultats) a été pris comme base et un filtre a été ajouté.
Ajouter un filtre et choisir la variable d'affichage de la position dans la liste déroulante. Choisir le type : >. Ensuite, il faut inscrire 0 dans Number (Nombre). Avec un tel filtre, vous pourrez supprimer tous les résultats ayant une position nulle.
Télécharger un exemple
Comment importer un exemple dans A-Parser
eJx1VNtu2zAM/RVDCNAVyIJ2a4HBDwPSbhk2dE3Wy1OSB8WiWy2y6OmSXoL8+yhZ
ttNufYgi3g55SMpb5rhd25kBC86yfL5ldbyznF1/zfMvvliH3zfM8xla6STq7H12
zTeQCay41DZ7kO4evct49gwGszq5sSGrubFgAuz8TTRyE1Byrxwbbpl7qoFS4waM
kQLIKAXJ3kJt8PGJ5A1XnlxKrizs3o4o0VTcEZUI3EaxwcqrdXEPxXrUeLw7GDQ8
iNWgLX2x0AeHbA+9lMqBIZwEmM9ZBxR4tlyWw+R608R93kt9RHeso1vOLGjLdstl
i2gnsZpQYX08SiPojKHdN9jUAb16QtIlryIvwR0Ea0vrcOQeAwIXIpbGVZMhDKPP
eqvln1icRvKlq5FgJwYrUjmIAEH51FY3Z4MoB6I+xv5qYtJAhsxSqRNOhYjXFklt
4Q7NNPaA9FuGeqzUBWxA9W4R/8xLJWhzxiUFfU+B/3eZ/oOx6+jtp6L9eDBUQ4cS
pbPpzz5K4AXeEXOxIt5KVtKRbM/Ra5fmtwaou55dhp5VaKBLk5BTdnpUNeiwjP3I
xnWvekHjxVheKgvUpbybpgVvPb2+oZc71edY1QoCL+2VGoanctWvx9imMQShL/B1
8HlMEai3T5E5RGV/XDel1kbS+p2GAivq5H7WBFlwpW6vLvYtrF8pEhRox0fGD42M
fxpdSZ0VowKrbOGPTj6KeEI8P/T3k+N4NppPjesqnqd9WDKHGRX0Eu6QdpT6tFt2
H6HuE7d9+1OUb3e0Br/trAkJPQsBpKPm2+hxvPsLSinNVw==
Voir aussi : Filtres de résultats
Déduplication des liens
Déduplication des liens par domaine
Extraction de domaines
Suppression des balises des ancres et des snippets
Filtrage des liens par inclusion
Paramètres possibles
Prend en charge tous les paramètres du scraper SE::DuckDuckGo, ainsi que de plus :
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Result format | $domain - $key: $position\n | Format de sortie des résultats par défaut |
| Stop when found | ☑ | Arrêter la collecte si le domaine est trouvé, ne passera pas aux pages suivantes |
| Match type | Exact domain | Possibilité de comparer la position recherchée par domaine, par domaine principal et par lien complet (Exact domain / Top level domain / Exact url) |