FreeAI::Perplexity - Scraper för AI-tjänsten Perplexity
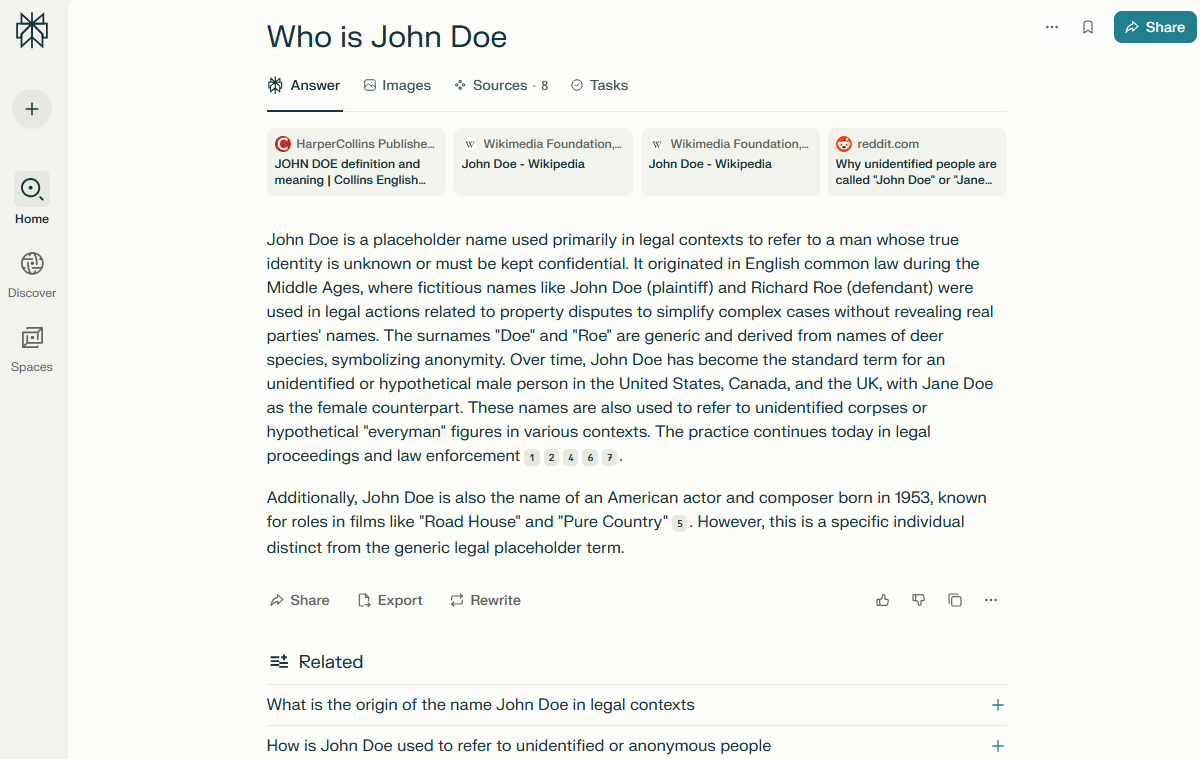
Översikt av scraper
Perplexity scraper är ett modernt verktyg för att samla in strukturerad information från en av de snabbast växande AI-sökmotorerna. Tack vare integrationen med Perplexity får du inte bara listor med länkar, utan aktuella, sammanfattade och relevanta svar baserade på ett stort antal källor, inklusive vetenskapliga artiklar, bloggar, forum och nyhetsportaler.
Perplexity scraper stöder frågor på naturligt språk, inklusive förtydliganden, kontextuella frågor och nästlade konstruktioner. Scrapern ger möjlighet att skrapa relevanta frågor genom att automatiskt lägga till dem i frågekön, vilket avsevärt utökar mängden insamlad information.
Bearbetningshastigheten når 500–800 frågor per minut tack vare flertrådning. Beroende på konfiguration och använda förinställningar kan du få tusentals unika textfragment och länkar inom några minuter.
Resultaten kan sparas i valfritt format tack vare den kraftfulla mallmotorn Template Toolkit, som gör det möjligt att strukturera data i JSON, CSV, SQL och andra format, samt tillämpa filtrering, sortering och aggregering av data i realtid.
Perplexity scraper är idealisk för uppgifter inom konkurrensanalys, insamling av fakta och citat, skapande av kunskapsbaser, nyhetsövervakning och ämnesanalys, tack vare den höga kvaliteten och kontexten i de levererade resultaten.
Data som samlas in
- Svarstext (i Markdown-formatering)
- Länkar, ankare och snippets från datakällor
- Lista över liknande frågor
Funktioner
- Val av typ av informationskälla (stöder flerval)
- Automatisk tilläggning av liknande frågor i frågekön upp till angivet djup
- Kringgående av skydd och stöd för sessioner för stabilare och snabbare drift
Användningsfall
- Insamling av strukturerade svar på tematiska frågor för att skapa kunskapsbaser, innehållsplaner, referenssystem och generera FAQ
- Extrahering av källänkar med ankare och snippets - perfekt för att bygga listor över auktoritativa resurser, citering och insamling av bakåtlänkar
- Insamling av liknande/förtydligande frågor från Perplexity-resultat - användbart för att analysera användarintresse, forma semantiska kärnor och generera idéer för artiklar
- Övervakning av omnämnanden av varumärken, produkter eller personer - kopplat till kontext och källor
- Sökning och analys av expertutlåtanden, trender och insikter från auktoritativa källor
- Snabb kontroll av aktualitet och fullständighet i information om nyckelämnen
- Automatisering av konkurrentanalys: vilka resurser citeras, vilka ämnen täcks och hur ofta
- Stöd för forsknings- och analysprojekt som kräver aggregering av exakt information från olika källor
- Alla andra uppgifter där det krävs att snabbt få korta, exakta svar med bekräftelse från verkliga källor och logisk kontext
Frågor
Som frågor ska sökfrågor anges på samma sätt som om de skrevs in direkt i Perplexitys sökfält, till exempel:
Hur lär man sig att lära sig snabbt?
Hur förbättrar man minne och koncentration?
Vad är en scraper?
TOPP 10 webbplatser i ryska internet
Resultat
Här och framåt är exempelresultaten förkortade för bättre tydlighet
Som standard visas frågan och svaret på den, till exempel:
Vad är en scraper?
En scraper — är ett program eller skript som automatiskt samlar in, analyserar och systematiserar information från olika källor, oftast från webbplatser[1][2][5][7]. Huvuduppgiften för en scraper — är att extrahera nödvändiga data (t.ex. texter, priser, kontakter, bilder) från strukturerade eller semistrukturerade informationsmängder, såsom HTML-sidor, databaser, textfiler och andra format[1][5][6].
**Hur en scraper fungerar:**
- Skannar angivna datakällor (t.ex. webbsidor).
...
TOPP 10 webbplatser i ryska internet
## TOPP-10 webbplatser i Runet i juni 2025
Baserat på färska data från Similarweb och andra analysresurser inkluderar listan över de mest besökta webbplatserna i det ryska segmentet av internet (Runet) följande resurser:
1. **Yandex.ru** — den största ryska sökmotorn och internetportalen[2][6].
2. **Google.com** — global sökmotor som används flitigt även i Ryssland[2][6].
...
### Tabell för tydlighet
| Plats | Webbplats | Huvudfunktion |
|-------|----------------|------------------------------|
| 1 | yandex.ru | Sök, tjänster, portal |
| 2 | google.com | Sök |
...
Alternativ för resultatvisning
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att visa resultat i valfri form, även strukturerat som CSV eller JSON.
Export av länklista
Resultatformat:
$sources.format('$link\n')
Exempel på resultat:
https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82%D0%BA%D0%BE%D0%B9%D0%BD
https://www.kaspersky.ru/resource-center/definitions/what-is-bitcoin
https://dzengi.com/ru/chto-takoe-bitcoin-prostim-yazikom
https://www.sberbank.ru/ru/person/kibrary/vocabulary/bitkoin
https://help.cryptopay.me/ru/articles/3414939-%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-%D0%B1%D0%B8%D1%82%D0%BA%D0%BE%D0%B8%D0%BD
...
Utmatning till CSV av länkar, ankare och snippets med deras positioner
Resultatformat:
[% FOREACH item IN sources;
tools.CSVline(loop.count, item.link, item.anchor, item.snippet);
END %]
Exempel på resultat:
...
6,https://www.kraken.com/ru/learn/what-is-bitcoin-btc,"Vad är Bitcoin (BTC)? fullständig guide - Kraken","Lär dig om Bitcoins decentraliserade natur, begränsade utbud och dess roll som digital valuta. Upptäck vad som ligger till grund för BTC, vilka dess huvudprinciper och användningsfall är."
7,https://www.vedomosti.ru/finance/articles/2024/09/23/1064026-bitkoin,"Vad är bitcoin och varför behövs det - Vedomosti","Detta är en digital valuta som används som betalningsmedel och finansiell tillgång"
8,https://forklog.com/cryptorium/chto-takoe-bitkoin,"Vad är bitcoin och hur fungerar det med enkla ord? - ForkLog","Bitcoin — är ett decentraliserat system baserat på principen om direktutbyte mellan användare. För transaktioner används kryptovalutan med samma namn BTC."
I Allmänt resultatformat används mallmotorn Template Toolkit för att skriva ut arrayen $sources i en FOREACH-loop.
I resultatfilens namn behöver du bara ändra filändelsen till csv.
Utmatning till JSON av fråga, svar och lista över liknande frågor
Allmänt resultatformat:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.query = query;
obj.answer = p1.answer;
obj.related = [];
FOREACH item IN p1.related;
obj.related.push(item.text);
END;
obj.json %]
Starttext:
[
Sluttext:
]
Exempel på resultat:
[{"related":["Varför anses bitcoin vara den första kryptovalutan och hur skiljer den sig från traditionella pengar","Hur fungerar blockkedjetekniken som ligger till grund för bitcoin","Vilka kryptografiska metoder skyddar transaktioner i bitcoinsystemet","Varför gör begränsningen på 21 miljoner mynt bitcoin till en unik tillgång","Vilka fördelar ger decentralisering och avsaknad av mellanhänder vid användning av bitcoin"],"answer":"**Bitcoin** (Bitcoin, BTC) — är den första och mest kända kryptovalutan, som utgör ett decentraliserat digitalt betalningssystem baserat på blockkedjeteknik. I detta system registreras alla transaktioner i en offentlig liggare (blockkedja), som är skyddad med kryptografiska metoder och tillgänglig för kontroll för alla nätverksdeltagare[1][3][4].\n...","query":"Vad är bitcoin?"},{"related":["Vilka är de viktigaste reglerna och tipsen för att googla rätt","Varför är det viktigt att undvika frågor och komplexa meningar vid sökning","Hur man använder engelska för effektivare sökning i Google","Vilka operatorer och symboler hjälper till att utöka eller förtydliga sökningen","Vad är skillnaden mellan att använda citattecken och tilde vid informationssökning"],"answer":"## Hur man googlar rätt: grundläggande tips\n\n**Formulera frågor kort och koncist**\n- Använd 2–6 nyckelord, undvik långa frågor och komplexa meningar. Till exempel, istället för \"vad ska jag göra om internet inte fungerar på min dator med windows?\" använd \"internet fungerar inte windows hur man fixar\"[1].\n\n**Sök efter exakta fraser**\n...","query":"Hur man googlar rätt?"}]
Möjliga inställningar
| Namn på parameter | Standardvärde | Beskrivning |
|---|---|---|
| Sources | Web | Typ av informationskälla (stöder flerval) |
| Use sessions | ☑ | Sparar bra sessioner, vilket gör det möjligt att skrapa ännu snabbare med färre fel |
| Bypass CloudFlare | ☑ | Automatiskt kringgående av CloudFlare-skydd |
| Bypass CloudFlare Browser Max Pages | 10 | Max antal sidor vid kringgående av CF |
| Bypass CloudFlare Browser Headless | ☑ | Om alternativet är aktiverat kommer webbläsaren inte att visas under kringgående av CF |