Check::BackLink - 根据链接库检查链接是否存在
爬虫工具概览
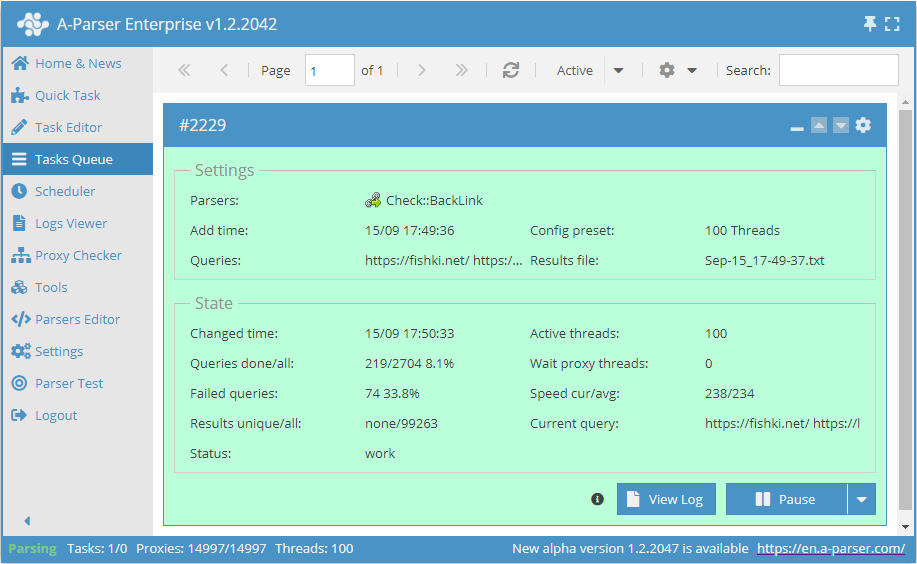
该爬虫工具允许您检查反向链接(backlinks),即指向您网站的页面链接。
A-Parser 的功能允许您保存数据抓取设置以便将来使用(预设)、设置数据抓取计划等等。
得益于内置强大的模板引擎 Template Toolkit,您可以按所需的任何形式和结构保存结果,该引擎允许对结果应用额外的逻辑,并以各种格式输出数据,包括 JSON、SQL 和 CSV。
爬虫工具应用场景
🔗 反向链接监控
定期检查反向链接,并将结果追加写入 SQLite 数据库表
采集的数据
- 页面上外部链接和内部链接的总数
- 检查指定页面上是否存在链接
0和10- 表示没有完全匹配的反向链接1- 表示存在完全匹配的反向链接
- 检查指定页面是否通过 robots.txt 禁止访问 -
0和1 - 检查是否通过带有
noindex属性的 robots 元标签 禁止页面索引,以及是否通过nofollow属性禁止追踪链接 - 检查是否通过
rel=nofollow属性禁止追踪链接
可以获取的其他数据:
- 页面上外部链接和内部链接的数量
- 页面上所有外部链接和内部链接的列表
功能
- 检查指定页面上是否存在链接,并支持通过字符串包含关系搜索不带协议头的链接
- 检查页面是否通过 robots.txt 禁止索引
- 检查 robots 元标签 是否包含
noindex和nofollow属性 - 检查找到的链接是否包含
rel=nofollow - 通过字符串包含关系搜索链接
- 支持指定自定义的 User-Agent 请求头
使用案例
- 检查自己的链接是否在指定页面上发布
- 搜索仅对特定 User-Agent(例如 Google 机器人)显示的链接
查询
在查询中,需要指定要查找链接的页面,并用空格分隔要查找的链接:
https://fishki.net/ https://lenta.ru/news/2020/12/18/lavina/
https://en.wikipedia.org/wiki/Moscow https://lenta.ru/news/2005/12/23/city/
http://soccerjerseys.in.net/ https://lenta.ru/news/2012/03/12/homeless/
https://tjournal.ru/ https://lenta.ru/articles/2016/02/15/deathlab/
查询占位符
您可以使用 内置宏 自动从文件中插入子查询,例如我们想根据页面库检查网站,指定要在其中查找链接的页面列表:
https://fishki.net/
https://en.wikipedia.org/wiki/Moscow
http://soccerjerseys.in.net/
https://tjournal.ru/
在查询格式中指定从文件 backlinks.txt 插入额外查询的宏,此方法允许检查网站库中是否存在文件中的链接列表:
$query {subs:backlinks}
该宏将为每个原始搜索查询创建与文件中数量相同的额外查询,宏运行后的结果总数为 [原始查询数量(页面链接)] x [backlinks 文件中的查询数量] = [总查询数量]。
还可以在查询格式中指定协议,以便仅使用域名作为查询:
http://$query
此格式将为每个查询添加 http://。
结果输出示例
得益于内置的模板引擎 Template Toolkit,A-Parser 支持灵活的结果格式化,这使其能够以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
默认输出
结果格式:
$backlink - $checklink: $exists, blocked by robots.txt: $robots\n
结果示例,其中显示了反向链接、进行反向链接搜索的页面链接、是否存在反向链接,以及检查页面是否在 robots.txt 文件中被屏蔽:
http://soccerjerseys.in.net/ - https://lenta.ru/news/2012/03/12/homeless/: 1, blocked by robots.txt: 0
https://tjournal.ru/ - https://lenta.ru/articles/2016/02/15/deathlab/: 0, blocked by robots.txt: 0
https://en.wikipedia.org/wiki/Moscow - https://lenta.ru/news/2005/12/23/city/: 0, blocked by robots.txt: 0
https://fishki.net/ - https://lenta.ru/news/2020/12/18/lavina/: 0, blocked by robots.txt: 0
将反向链接的存在情况及用于分析反向链接和页面的额外参数输出到 CSV 表格
内置工具 $tools.CSVLine 允许创建正确的表格文档,以便导入 Excel 或 Google 表格。
仅当页面上存在反向链接时,变量 $actualchecklink 才有结果,如果不存在反向链接,则该变量的结果为 none。$actualbacklink 和 $actualchecklink 是重定向后的真实链接。
结果格式:
[% tools.CSVline(backlink, checklink, anchor, nofollow, noindex, redirect, exists, robots, actualbacklink, actualchecklink, intcount, extcount) %]
文件名:
$datefile.format().csv
起始文本:
Backlink,Checklink,Anchor,Nofollow,Noindex,Redirect,Exists,Robots,Actualbacklink,Actualchecklink,Intlinks count,Extlinks count
结果示例:
https://tjournal.ru/,https://lenta.ru/articles/2016/02/15/deathlab/,none,0,0,0,0,0,https://tjournal.ru/,none,112,37
https://fishki.net/,https://lenta.ru/news/2020/12/18/lavina/,none,0,0,0,0,0,https://fishki.net/,none,966,31
http://soccerjerseys.in.net/,https://lenta.ru/news/2012/03/12/homeless/,"get more information",0,0,0,1,0,http://soccerjerseys.in.net/,https://lenta.ru/news/2012/03/12/homeless/,89,20
https://en.wikipedia.org/wiki/Moscow,https://lenta.ru/news/2005/12/23/city/,none,0,0,0,0,0,https://en.wikipedia.org/wiki/Moscow,none,2733,598
...
下载示例
eJx9VE1v4jAQ/SuR1UqtRGOg6mqVG6AidUWhS9u9UA5uMgE3jp21HaBC/Pcd5xPK
7t484zdvxjNvvCeWmcQ8aTBgDQkWe5IVZxKQ+x1LMwFeuIYw8d5ZmAguE+OxKPIy
plkKFrQhHYKGcadgsSAjBw6CIaIniMbbCGKWC0uWyw5BajyasdIpcykWlzeeVUoY
f/T8C9nhKuv5daaOh0aRvLGYDNdKF0epYiWE2lYGlxHsirOGiGsIbWHAjhtrSr96
V9WRhTZn4iRP6TrNxqUNVS5rptK49m4ul6R5yjPbwIvCp8RcQOseozXFDuHFRcQs
uFs/Lp59de3bnUUo9pFbriQTZT9cA9sevUr+O3fxUiEWj5qDGWuVostCQeCcn3Uv
F+SisAlS5EXszzKGBDETBjrEYKljhoVEX284DpJZpWeZqwf9e6LkQIgJbEC0sIJ/
mHMR4bQHMQY9VIF/h8zOOA7N845TbUBvNdbQsBTWcPbYRkVqolZ1MwRPuUXbjNxA
0NtFZwKQNT2bOliqNDRprM6hSY5yz0BGCBzWGhg1kx+UGpvW+ppW2prXurovNTUv
9TQ41dLgi44epC23plTS/e7YfJOtYgZZVRL50sUTVZw6QyVjvpph/zSPoEbm8gV3
eiZHyq2va6vMhUBVGJi36hyYSgXOaDp/FjwqUmBZ9Rp3SLGwP57LUjPNUf13rsAU
B3mctaIMmRCv88nxDWkVjcba2swElMbcrBPuS7DUq30CpGW+zqmEraH9br9Le33a
+04F23DJ6JuskSD9LU94hlNivtIr6iz6qEyotv+k6945uv4tDbn9rMgQZlQYgv7A
PsOnwW/g/zUhQ/fW8axVCgKMOarKfqhc44Y7+DkB05aHGOFIvtEuPuyORsDsWrB3
SlzrLKwU7jQO9rBsPtrmt96ffbfB/oDb8mGeSqSbrcOhD0VicBVI0Dv8AQ3PGZI=
结果格式中应用了 Template Toolkit 模板引擎。
在结果文件名中,只需将文件扩展名更改为 csv。
要使“Prepend text”选项在任务编辑器中可用,需要激活“More options”。 在“Prepend text”中按逗号分隔写入列名,并将第二行留空。
将反向链接页面中的外部链接转储为 JSON
结果格式:
[% data = {};
data.query = query; data.links = [];
FOREACH item IN extlinks;
data.links.push(item.link);
END;
IF !firstString;
",\n";
ELSE;
firstString = 0;
END;
data.json %]
起始文本:
[% firstString = 1 %][
结束文本:
]
结果示例:
[{"query":"https://tjournal.ru/ https://lenta.ru/articles/2016/02/15/deathlab/","links":["https://vc.ru/job","https://vc.ru/job/new","https://vc.ru/job","https://twitter.com/aktroitsky","https://twitter.com/aktroitsky/statuses/1382294384931188748","https://twitter.com/aktroitsky/statuses/1382294384931188748","https://t.co/fD4AiCpbrV","https://twitter.com/aktroitsky/statuses/1382294384931188748"]}]
结果处理
A-Parser 允许在数据抓取过程中直接处理结果,在本节中,我们列出了 Check::BackLink 爬虫工具最受欢迎的使用案例
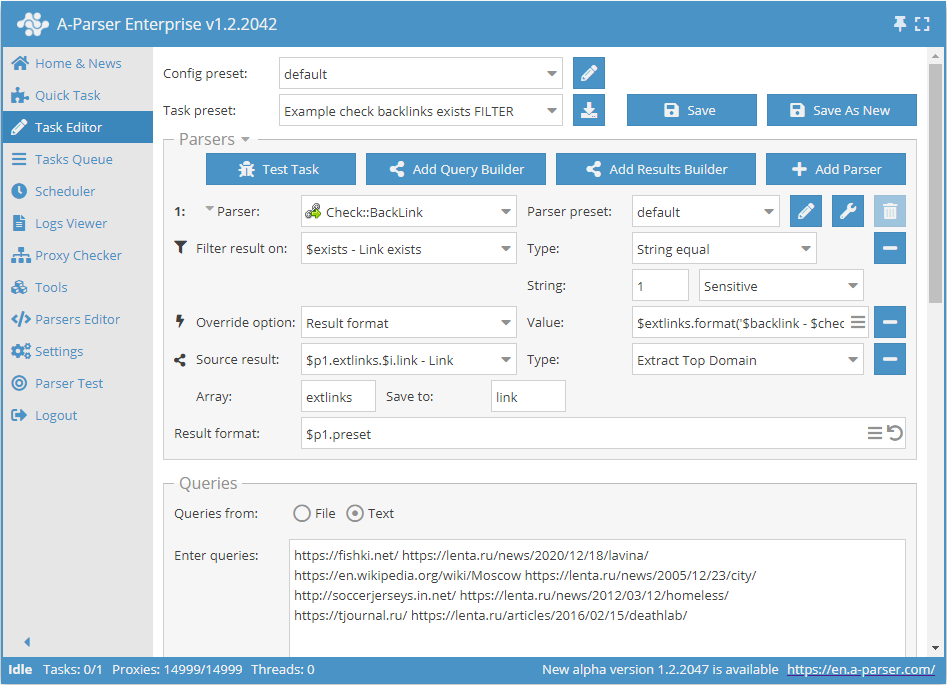
在存在反向链接时保存外部链接的域名
添加过滤器,并在下拉列表中选择信任变量 $exists - Link exists。选择类型:String equal。接着需要在String (字符串)字段中输入代表存在反向链接的值 1。通过此过滤器,您可以输出所有存在反向链接的结果。
添加Result Builders (结果构造器),并在下拉列表中选择来源:$p1.extlinks.$i.link - Link。选择类型:Extract Top Domain。这样就可以从外部链接中获取域名。
下载示例
eJx9VNtuGjEQ/RVkIaWR6C4Qpar2jdAgpSIhJeSJ5MHZHcDBa29sLxch/r0z3hsp
bd88M2fO3H1gjtu1fTRgwVkWzQ8s828WsdsdTzMJrXgF8br1xuO1FGptW7AT1tnW
6G48u52yDsu4sWDIec6GhI2iGwSPEYzWBBY8l451DsztM0DehZAODJowEFkiVjCi
pjDNChx85FyicsNlTnIP3zpzQisULCjLjg2p3oAxIgHEiISCaJNyV0ZoONqwc76K
oAB8uWhXhbW+ttq+1Eoo68QXaV5e1MUlO76+VnnbkWcg0qwXlF2rjU98AzNdVAuN
eoTSA099Kgl3QNYqlcvA7YiBJ4mgKrksIlBnm6jPSnz4UpRGLD6NADsyOkWVA09A
yn2V3Zy1vcyQIve+vwofFi24tNBhFlMdcUwk+dMicBjcaTPxXUf9gWk1kHIMG5AN
zPPf5EImuAaDBTrdlY5/h0zOOI51eaehcKRbgznULF66mdw3Xoke62XVDClS4VC2
Q50rGkwXlWuArO7ZA8FSbaAO40wOdXA8gwwUrU8zsUHWqD5V8WkqJ8oDszo3MYab
dztzVi2czw8vghao3Fk0GR67mc5+6JQLRbM3hu8LU+XlaIu86xFdY60WYjkpt71K
IlczPOOJGmq6WOqYyqXEgVuYNos3sOWASaibeuY89CEwaH26mIOW9udT0YXMCEzp
mmpPcUanUUvKmEv5PB2fWlizrCisnMtsFIYLYVdrEShwYavSSVCOByYPFWxt2O/2
u2GvH/a+h5JvhOLhi6qQoIKtWIsMEsEDbZYhSeG9trHe/pOue010/aswFm5fkiHM
6jgG844jhL0NhPp/TsjQvSKelU5BgrUnWbl3HD8eL8HPCbhxIkYPIvkWdrGw6zAB
7laSv4WMWudgqfFccbA07/JzrT/ow9kXGx2OeAjv9rFA0mwJhzpcEut/y97xN4Qy
DUs=
可能的设置
支持爬虫工具  HTML::LinkExtractor 的所有设置,此外还包括:
HTML::LinkExtractor 的所有设置,此外还包括:
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Check robots.txt | ☑ | 确定是否检查 robots.txt 对页面索引的禁止 |
| Match link by substring | ☐ | 确定是否通过字符串包含关系搜索链接。可以检查不带协议头的链接,例如通过不带 http 协议的域名 |