SE::Dogpile - Scraper de résultats de recherche Dogpile
Présentation du scraper
Scraper de la page de résultats de recherche Dogpile. Grâce au scraper SE::Dogpile, vous pourrez obtenir de grandes bases de liens prêts pour une utilisation ultérieure. Vous pouvez utiliser les requêtes de la même manière que vous les saisissez dans la barre de recherche Dogpile, y compris les opérateurs de recherche (url, language, site, etc.).
Les fonctionnalités d'A-Parser permettent de sauvegarder les paramètres de collecte de données du scraper Dogpile pour une utilisation ultérieure (présélections), de définir des calendriers de collecte et bien plus encore. Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, le brassage de combinaisons alphanumériques et de listes pour obtenir le maximum de résultats possible.
La sauvegarde des résultats est possible dans la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarit intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'exporter les données dans divers formats, y compris JSON, SQL et CSV.
Données collectées
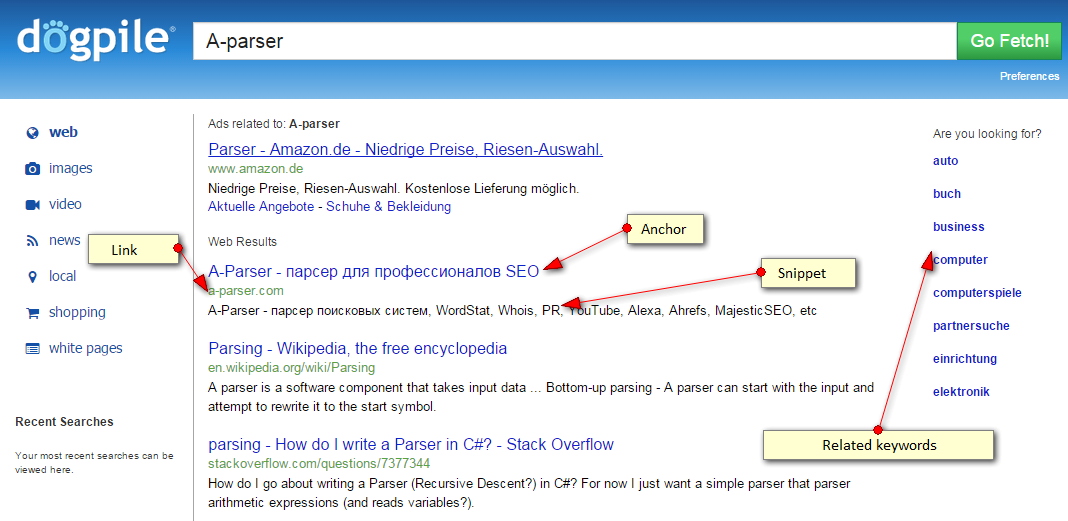
- Liens, ancres et snippets des résultats
- Liste de mots-clés associés (Related keywords)
Possibilités
- Scrape le nombre maximum de résultats fournis par Dogpile - 50 pages de 10 éléments par résultat
- Nombre total de résultats - 500
- Possibilité de rechercher des mots-clés associés
Cas d'utilisation
- Collecte de bases de liens - pour A-Poster, XRumer, AllSubmitter, etc.
- Évaluation de la concurrence pour les mots-clés
- Recherche de backlinks (mentions) de sites
- Vérification de l'indexation des sites
- Recherche de sites vulnérables
- Toute autre variante impliquant la collecte de données Dogpile sous une forme ou une autre
Requêtes
Comme requêtes, il est nécessaire d'indiquer des expressions de recherche, exactement comme si elles étaient saisies directement dans le formulaire de recherche Dogpile, par exemple :
test
parser language: ru
site: a-parser.com
site: slideshare.net Java Developer gmail.com resume -sample -samples -example -templates
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour multiplier les requêtes, par exemple si nous voulons obtenir une très grande base de forums, indiquons quelques requêtes de base dans différentes langues :
forum
forum
foro
论坛
Dans le format de requête, indiquons un brassage de caractères de a à zzzz, cette méthode permet de faire pivoter au maximum les résultats de recherche et d'obtenir de nombreux nouveaux résultats uniques :
$query {az:a:zzzz}
Cette macro créera 475254 requêtes supplémentaires pour chaque requête de recherche initiale, ce qui donnera au total 4 x 475254 = 1901016 requêtes de recherche, un chiffre impressionnant, mais ce n'est pas du tout un problème pour A-Parser. À une vitesse de 2000 requêtes par minute, une telle tâche sera traitée en seulement 16 heures.
Utilisation d'opérateurs
Vous pouvez utiliser des opérateurs de recherche dans le format de requête, ainsi il sera automatiquement ajouté à chaque requête de votre liste :
site:$query
Variantes d'affichage des résultats
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme libre, ainsi que structurée, par exemple CSV ou JSON
Exportation d'une liste de liens
Liens + ancres + snippets avec affichage de la position
Affichage des liens, ancres et snippets dans un tableau CSV
Sauvegarde des mots-clés associés
Vérification de l'indexation des liens
Sauvegarde au format SQL
Dump des résultats en JSON
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte, dans cette section nous avons listé les cas les plus populaires pour le scraper Dogpile
Déduplication des liens
Déduplication des liens par domaine
Extraction de domaines
Suppression des balises des ancres et snippets
Filtrage des liens par inclusion
Paramètres possibles
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Pages count | 10 | Nombre de pages à scraper (de 1 à 50) |
| Bypass CloudFlare with Chrome | ☑ | Contournement automatique de la vérification CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 10 | Nombre max. de pages lors du contournement CF via Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Si l'option est activée, le navigateur ne sera pas affiché pendant le contournement CF via Chrome |