SE::Yandex::WordStat::ByDate - Scraper de statistiques d'impressions Yandex WordStat par mois ou par semaines
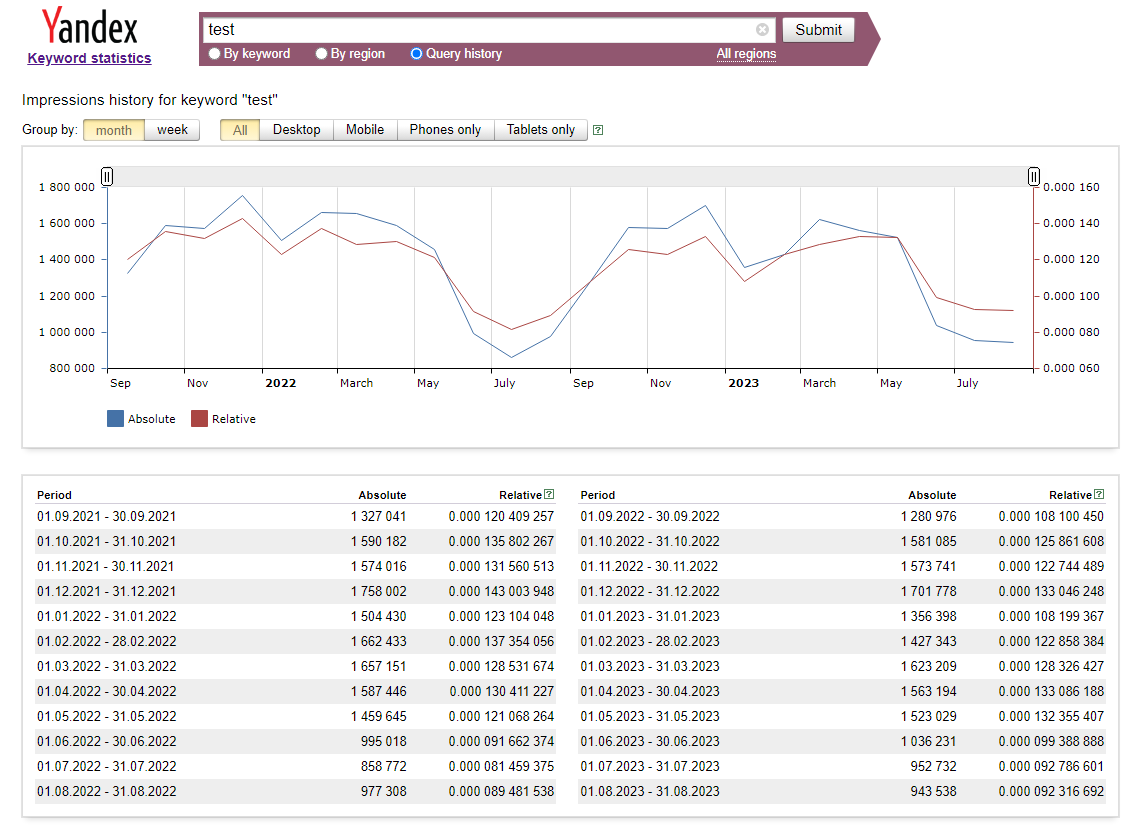
Présentation du scraper
Wordstat est un service de Yandex conçu pour évaluer l'intérêt des utilisateurs pour diverses thématiques et pour la sélection de mots-clés pour l'optimisation SEO et la publicité contextuelle. De plus, avec Wordstat Yandex, il est possible d'évaluer la saisonnalité et la dépendance géographique des requêtes de recherche.
Le scraper Yandex WordStat by date prend en charge la multiplication automatique des requêtes, vous pouvez être sûr d'obtenir le nombre maximum de résultats de la délivrance. De plus, A-Parser peut passer automatiquement par les requêtes associées jusqu'à la profondeur indiquée.
La fonctionnalité d'A-Parser permet de sauvegarder les paramètres de collecte de données pour une utilisation ultérieure (présélections), de définir un calendrier de collecte et bien plus encore. Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, l'itération de combinaisons alphanumériques et de listes pour obtenir le plus grand nombre possible de résultats.
La sauvegarde des résultats est possible sous la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarit intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'afficher les données dans divers formats, y compris JSON, SQL et CSV.
Cas d'utilisation du scraper
🔗 Automatisation Wordstat bydate
Utilisé pour stocker des informations à jour dans la base de données, et génère un fichier csv avec des données fraîches à chaque exécution
Comptes
Pour le fonctionnement du scraper  SE::Yandex::WordStat::ByDate, des comptes Yandex sont nécessaires. Les comptes peuvent être enregistrés à l'aide du scraper
SE::Yandex::WordStat::ByDate, des comptes Yandex sont nécessaires. Les comptes peuvent être enregistrés à l'aide du scraper  SE::Yandex::Register ou simplement en ajoutant des comptes existants dans le fichier
SE::Yandex::Register ou simplement en ajoutant des comptes existants dans le fichier files/SE-Yandex/accounts.txt au format supporté.
Ou vous pouvez activer l'enregistrement des comptes "à la volée".
Données collectées
- Statistiques des mots-clés par mois ou par semaine
- Date
- Valeur absolue
- Valeur relative
Possibilités
- Prend en charge le choix de la région de recherche (avec sous-groupes)
- Possibilité de choisir plusieurs régions à la fois pour l'évaluation
- Prise en charge du contournement automatique de Smart captcha et possibilité de contourner le captcha graphique à l'aide du service AntiCaptcha ou de tout autre service prenant en charge leur API
- Choix du type d'appareil
- Possibilité de choisir la méthode d'authentification
- Possibilité d'enregistrer des comptes "à la volée"
- Prend en charge le travail avec le format étendu de comptes et sait répondre à la question secrète (si la réponse est dans
info). Utilise également pour l'authentification le proxy sauvegardé (s'il est présent dansinfo).
Cas d'utilisation
- Évaluation du volume de trafic par mot-clé
- Identification des mots-clés saisonniers
Requêtes
En tant que requêtes, il est nécessaire d'indiquer des mots-clés, exactement comme s'ils étaient saisis directement dans le formulaire de recherche Wordstat, par exemple :
test
Variantes d'affichage des résultats
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme arbitraire, ainsi que structurée, par exemple CSV ou JSON
Affichage par défaut
Format du résultat :
Views:\n$views.format('$date $count $relcount\n')
Le résultat affiche les statistiques des mots-clés par mois et par semaine :
Monthly:
2011-09-30 3010832 0.0008903808
2011-10-31 681432 0.0001825883
2011-11-30 628532 0.0001575008
2011-12-31 629072 0.0001495699
2012-01-31 561206 0.0001300651
2012-02-29 572039 0.0001290000
2012-03-31 614897 0.0001225754
2012-04-30 520433 0.0001185340
2012-05-31 521967 0.0001235327
2012-06-30 502568 0.0001299958
...
Weekly:
2012-09-16 118715 0.0001222877
2012-09-23 120799 0.0001211773
2012-09-30 137809 0.0001365837
2012-10-07 133929 0.0001313643
2012-10-14 140373 0.0001293922
2012-10-21 136014 0.0001242209
2012-10-28 148350 0.0001293328
2012-11-04 139556 0.0001232566
2012-11-11 154830 0.0001314057
2012-11-18 136458 0.0001147489
2012-11-25 149463 0.0001261401
2012-12-02 144724 0.0001197564
2012-12-09 149142 0.0001212195
2012-12-16 162864 0.0001298181
Affichage dans un tableau CSV
Format du résultat :
[% FOREACH i IN views;
tools.CSVline(query, i.count, i.date);
END %]
Exemple de résultat :
"test",9661734,2012-03-31
"test",8567243,2012-04-30
"test",9028986,2012-05-31
"test",6082099,2012-06-30
"test",5531950,2012-07-31
"test",5214663,2012-08-31
"test",6603865,2012-09-30
"test",9127457,2012-10-31
"test",9238652,2012-11-30
Sauvegarde au format SQL
Format du résultat :
[% FOREACH i IN views;
"INSERT INTO views VALUES('" _ query _ "', '"; i.count _ "', '"; i.relcount _ "', '"; i.date _ "')\n";
END %]
Exemple de résultat :
INSERT INTO serp VALUES('test', '9661734', '0.0019259985', '2012-03-31')
INSERT INTO serp VALUES('test', '8567243', '0.0019512785', '2012-04-30')
INSERT INTO serp VALUES('test', '9028986', '0.0021368683', '2012-05-31')
INSERT INTO serp VALUES('test', '6082099', '0.0015732140', '2012-06-30')
INSERT INTO serp VALUES('test', '5531950', '0.0013160071', '2012-07-31')
INSERT INTO serp VALUES('test', '5214663', '0.0013327945', '2012-08-31')
INSERT INTO serp VALUES('test', '6603865', '0.0015936909', '2012-09-30')
INSERT INTO serp VALUES('test', '9127457', '0.0018740506', '2012-10-31')
INSERT INTO serp VALUES('test', '9238652', '0.0018308715', '2012-11-30')
Dump des résultats en JSON
Format de sortie general:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.views = [];
FOREACH item IN p1.views;
obj.views.push({
date = item.date
relcount = item.relcount
count = item.count
});
END;
obj.json %]
Texte initial:
[
Texte final:
]
Exemple de résultat :
[{
"views": [
{
"count": "9661734",
"date": "2012-03-31",
"relcount": "0.0019259985"
},
{
"count": "8567243",
"date": "2012-04-30",
"relcount": "0.0019512785"
},
{
"count": "9028986",
"date": "2012-05-31",
"relcount": "0.0021368683"
}
]
}]
Voir aussi : Filtres de résultats
Paramètres possibles
| Paramètre | Valeur par défaut | Description |
|---|---|---|
| Period | Monthly | Choix de la période (Monthly/Weekly/Daily, Daily fonctionne uniquement avec l'option Use Wordstat 2 activée) |
| Start date | | Indication de la date à partir de laquelle effectuer la recherche. Fonctionne uniquement avec l'option Use Wordstat 2 activée. Il est impératif de respecter les règles d'indication de date |
| End date | | Indication de la date jusqu'à laquelle effectuer la recherche. Fonctionne uniquement avec l'option Use Wordstat 2 activée. Il est impératif de respecter les règles d'indication de date |
| Region | All | Région de recherche |
| AntiGate preset | default | Il est nécessaire de configurer préalablement le scraper  Util::AntiGate - indiquer votre clé d'accès et d'autres paramètres, puis choisir la présélection créée ici Util::AntiGate - indiquer votre clé d'accès et d'autres paramètres, puis choisir la présélection créée ici |
| AntiGate preset for Login | default | Présélection AntiGate pour la connexion. Il est nécessaire de configurer préalablement le scraper Util::AntiGate avec les paramètres, puis choisir la présélection créée ici |
| Type | All | Choix du type d'appareil |
| Accounts | Only from "accounts.txt" | Choix de la méthode de travail avec les comptes : Always auto register - toujours enregistrer automatiquement les comptes "à la volée", nécessite de choisir une présélection configurée dans le paramètre SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - les comptes existants de accounts.txt sont utilisés en premier, et s'ils sont épuisés, l'enregistrement automatique "à la volée" est utilisé, pour lequel il faut choisir une présélection configurée dans le paramètre SE::Yandex::Register preset. Only from "accounts.txt" - utiliser uniquement les comptes existants de accounts.txt, et s'ils sont épuisés, attendre le temps défini (paramètre Wait new accounts in "accounts.txt") l'apparition de nouveaux |
| Wait new accounts in "accounts.txt" | 0 | Temps d'attente pour l'apparition de nouveaux comptes dans accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Suppression automatique des "mauvais" comptes : Always - toujours supprimer. Always, except wrong login/password - toujours supprimer, sauf dans les cas où Yandex a signalé un identifiant/mot de passe incorrect. En effet, Yandex peut envoyer un tel message lors d'un bannissement d'IP pour un compte tout à fait fonctionnel, c'est pourquoi on peut optionnellement laisser ces comptes pour une réutilisation. Never - ne jamais supprimer. Indépendamment de l'option choisie, les comptes ne sont pas supprimés en cas d'erreurs de proxy/navigateur |
| SE::Yandex::Register preset | default | Choix de la présélection de paramètres pour SE::Yandex::Register |
| Authorization method | HTTP | Méthode d'authentification : HTTP - rapide, peu exigeant en ressources. Chrome - lent, exigeant en ressources, peut théoriquement prolonger la vie des comptes |
| Chrome headless | ☑ | Si l'option est activée, le navigateur ne sera pas affiché |
| Use sessions | ☑ | Utilisation des sessions |
| Do not reset session if authorization passed | ☑ | Ne pas réinitialiser la session en cas d'erreurs si le scraper est déjà authentifié |
| Use Wordstat 2 | ☐ | Utilisation de Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Permet de décharger immédiatement les 2000 résultats par requête sans passer par la pagination |