SE::Yandex::WordCraft - Scraper WordCraft. Sélection de requêtes et analyse de marché
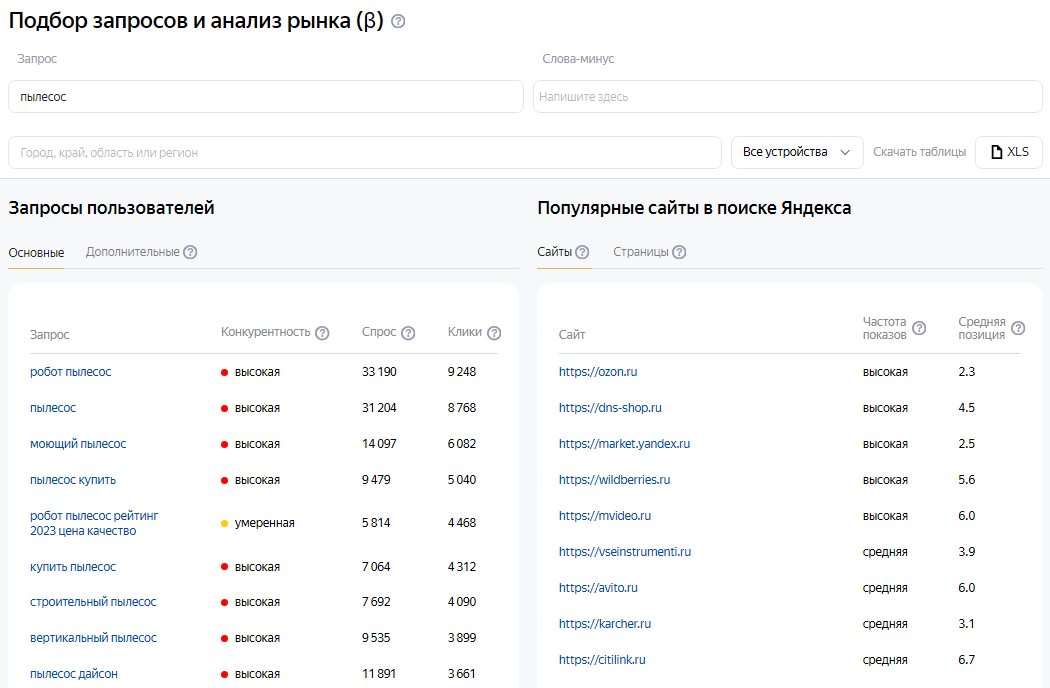
Présentation du scraper
Yandex WordCraft (Wordcraft) fait partie du service Yandex Webmaster, avec lequel vous pouvez sélectionner des requêtes cibles pour la promotion et la publicité, en tenant compte de la popularité et de l'environnement concurrentiel. Des centaines de millions de requêtes uniques sont disponibles pour l'analyse. La demande, les impressions, les clics et les positions sont présentés avec une moyenne mensuelle sur l'année écoulée.
Le scraper de requêtes Yandex WordCraft prend en charge la multiplication automatique des requêtes, vous pouvez être sûr d'obtenir le nombre maximum de résultats de la recherche.
La fonctionnalité d'A-Parser permet de sauvegarder les paramètres de collecte de données pour une utilisation ultérieure (présélections), de définir un calendrier de collecte de données et bien plus encore. Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, l'itération de combinaisons alphanumériques et de listes pour obtenir le plus grand nombre de résultats possible lors de la collecte de données Yandex Wordstat.
La sauvegarde des résultats est possible dans la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarits intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'afficher les données dans divers formats, notamment TXT, JSON, SQL et CSV.
Comptes
Pour le fonctionnement du scraper  SE::Yandex::WordCraft, des comptes Yandex sont nécessaires. Les comptes peuvent être enregistrés à l'aide du scraper
SE::Yandex::WordCraft, des comptes Yandex sont nécessaires. Les comptes peuvent être enregistrés à l'aide du scraper  SE::Yandex::Register ou simplement en ajoutant des comptes existants dans le fichier
SE::Yandex::Register ou simplement en ajoutant des comptes existants dans le fichier files/SE-Yandex/accounts.txt au format pris en charge.
Ou vous pouvez activer l'enregistrement des comptes "à la volée".
Pour utiliser l'autorisation par session, il est nécessaire que la ligne de données soit dans ce format :
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Données collectées
- Requêtes des utilisateurs (principales) :
- Requête, concurrence, demande, clics
- Requêtes des utilisateurs (supplémentaires) :
- Requête, concurrence, demande, clics
- Sites populaires dans la recherche Yandex (sites) :
- Site, fréquence d'impression, position moyenne
- Sites populaires dans la recherche Yandex (pages) :
- URL, fréquence d'impression, position moyenne, nombre de requêtes, titre
Cas d'utilisation
- Évaluation de la concurrence par mot-clé (demande, clics)
- Recherche de nouveaux mots-clés de thématique similaire
- Collecte de grandes bases de mots-clés de diverses thématiques
- Toutes autres options impliquant la collecte de données Yandex Webmaster WordCraft sous une forme ou une autre
Requêtes
En tant que requêtes, il est nécessaire d'indiquer des mots-clés, exactement comme si vous les saisissiez directement dans le champ de recherche de Wordcraft, par exemple :
aspirateur
seo
Options d'affichage des résultats
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarits intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme libre ainsi que structurée, par exemple CSV ou JSON
Affichage par défaut
Exemple d'affichage de la liste des requêtes des utilisateurs (principales). Format du résultat :
User queries general: $uqg.format('$query,$compet,$demand,$clicks\n')
Liste résultante :
aspirateur,HIGH,33190,9248
aspirateur,HIGH,31204,8768
aspirateur,HIGH,14097,6082
...
aspirateur,HIGH,791,656
Pour afficher les résultats en utilisant le Format général des résultats il faut indiquer le numéro du scraper dans la tâche - $p1. (parser 1) ou p1. si le moteur de gabarits Template Toolkit est utilisé. Par exemple :
User queries general: $p1.uqg.format('$query,$compet,$demand,$clicks\n')
Consultez Modification du format de résultat pour savoir ce qu'est le Format général des résultats
Affichage dans un tableau CSV
Exemple d'affichage de la liste des requêtes des utilisateurs (principales) dans un tableau CSV. Format du résultat :
[%
FOREACH uqg;
tools.CSVline(query,compet,demand,clicks);
END;
%]
Exemple d'affichage de la liste des requêtes des utilisateurs (supplémentaires) dans un tableau CSV. Format du résultat :
[%
FOREACH uqa;
tools.CSVline(query,compet,demand,clicks);
END;
%]
Exemple d'affichage de la liste des sites populaires dans la recherche Yandex (sites) dans un tableau CSV. Format du résultat :
[%
FOREACH rs;
tools.CSVline(site,popul,position);
END;
%]
Exemple d'affichage de la liste des populaires sites dans la recherche Yandex (pages) dans un tableau CSV. Format du résultat :
[%
FOREACH rp;
tools.CSVline(url,popul,position,queries,title);
END
%]
Voir aussi : Filtres de résultats
Options
- Parse queries for Rivals pages - lorsque cette option est activée, les requêtes populaires pour chacun des liens dans Rivals pages sont collectées. Les données collectées sont enregistrées sous forme d'objet JSON dans la variable
$rp.$i.queries_json. L'activation de cette option augmente considérablement le temps de collecte, car le scraper effectue de nombreuses sous-requêtes supplémentaires.
Paramètres possibles
| Paramètre | Valeur par défaut | Description |
|---|---|---|
| AntiGate preset | default | Il est nécessaire de configurer préalablement le scraper  Util::AntiGate - indiquer votre clé d'accès et d'autres paramètres, puis choisir la présélection créée ici Util::AntiGate - indiquer votre clé d'accès et d'autres paramètres, puis choisir la présélection créée ici |
| AntiGate preset for Login | default | Présélection AntiGate pour la connexion. Il est nécessaire de configurer préalablement le scraper Util::AntiGate avec les paramètres, puis choisir la présélection créée ici |
| Accounts | Only from "accounts.txt" | Choix de la méthode de travail avec les comptes : Always auto register - toujours enregistrer automatiquement les comptes "à la volée", nécessite de choisir une présélection configurée dans le paramètre SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - les comptes existants de accounts.txt sont utilisés en premier, et s'ils sont épuisés, l'enregistrement automatique "à la volée" est utilisé, pour lequel il faut choisir une présélection configurée dans le paramètre SE::Yandex::Register preset. Only from "accounts.txt" - utiliser uniquement les comptes existants de accounts.txt, et s'ils sont épuisés, attendre le temps défini (paramètre Wait new accounts in "accounts.txt") pour l'apparition de nouveaux. Only by session_id from "accounts.txt" - autorisation par cookies. |
| Wait new accounts in "accounts.txt" | 0 | Temps d'attente pour l'apparition de nouveaux comptes dans accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Suppression automatique des "mauvais" comptes : Always - toujours supprimer. Always, except wrong login/password - supprimer toujours, sauf dans les cas où Yandex a signalé un identifiant/mot de passe incorrect. Le fait est que Yandex peut donner un tel message lors d'un bannissement d'IP pour un compte tout à fait fonctionnel, donc on peut optionnellement laisser ces comptes pour une réutilisation. Never - ne jamais supprimer. Quel que soit le choix, les comptes ne sont pas supprimés en cas d'erreurs de proxy/navigateur |
| SE::Yandex::Register preset | default | Choix de la présélection de paramètres pour SE::Yandex::Register |
| Use sessions | ☑ | Utilisation des sessions |
| Do not reset session if authorization passed | ☑ | Ne pas réinitialiser la session en cas d'erreurs si le scraper est déjà autorisé |
| SE::Yandex::Register preset | default | Choix de la présélection de paramètres pour SE::Yandex::Register |