SE::Google::Suggest - Scraper de suggestions de recherche Google
Présentation du scraper
Scraper de suggestions de recherche par mots-clés dans Google. Grâce au scraper SE::Google::Suggest, vous pourrez collecter automatiquement des bases de mots-clés à partir des suggestions du moteur de recherche Google par requête. En utilisant le scraper SE::Google::Suggest, il est facile et rapide de collecter les suggestions Google par requête en fonction du pays, de la langue ou du domaine sélectionnés.
Le scraper de suggestions Google résout l'une des tâches principales du SEO, à savoir l'obtention automatisée et rapide d'un noyau sémantique étendu. Les suggestions de recherche Google permettent de couvrir un nombre maximal de phrases, et en combinaison avec le scraper de mots-clés Google -  SE::Google::KeywordPlanner, vous obtiendrez une sémantique la plus complète possible, ce qui aidera à attirer plus de trafic organique.
SE::Google::KeywordPlanner, vous obtiendrez une sémantique la plus complète possible, ce qui aidera à attirer plus de trafic organique.
Grâce au traitement multithread d'A-Parser, la vitesse de traitement des requêtes peut atteindre 6000 requêtes par minute, ce qui permet en moyenne d'obtenir jusqu'à 45000-46000 résultats par minute.
Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, l'itération de combinaisons alphanumériques et de listes pour obtenir le maximum de résultats possible. En utilisant le filtrage des résultats, vous pouvez immédiatement nettoyer le résultat en supprimant tous les déchets inutiles (en utilisant des mots-clés négatifs).
La fonctionnalité d'A-Parser permet de sauvegarder les paramètres de collecte de données du scraper SE::Google::Suggest pour une utilisation ultérieure (présélections), de définir un calendrier de collecte et bien plus encore.
La sauvegarde des résultats est possible dans la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarit intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'exporter les données dans divers formats, y compris JSON, SQL et CSV.
Cas d'utilisation du scraper
🔗 JS::Google::FromSnippets
Exemple de travail dans les scrapers JS avec des scrapers intégrés
Données collectées
- Nombre de résultats par requête
- Suggestions pour la requête
- Type de suggestion (0 - humaine, 1 - artificielle)
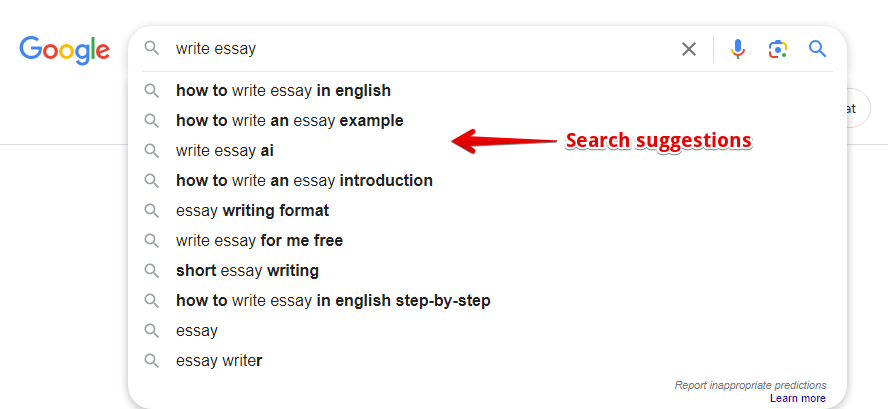
Fonctionnalités
- Prend en charge le choix du pays de recherche, du domaine et de la langue des résultats
- Possibilité de choisir la source à utiliser pour collecter les suggestions (option Client)
- Possibilité de supprimer les balises HTML des résultats de la collecte (option Remove HTML tags)
Cas d'utilisation
- Collecte de bases de mots-clés
Requêtes
Il est nécessaire d'indiquer des expressions de recherche comme requêtes, par exemple :
write essay
Football
Waterfall
Speak in english
Cats and dogs
forex
cheap essay
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour la substitution automatique de sous-requêtes à partir de fichiers. Par exemple, si nous voulons ajouter une liste d'autres mots à chaque requête, indiquons quelques requêtes de base :
essay
article
thesis
Dans le format des requêtes, indiquons la macro de substitution de mots supplémentaires à partir du fichier Keywords.txt. Cette méthode permet d'augmenter considérablement la variabilité des requêtes :
{subs:Keywords} $query
Cette macro créera autant de requêtes supplémentaires qu'il y en a dans le fichier pour chaque requête de recherche initiale, ce qui donnera au total [nombre de requêtes initiales] x [nombre de requêtes dans le fichier Keywords] = [nombre total de requêtes] suite au travail de la macro.
Par exemple, si le fichier Keywords.txt contient :
buy
cheap
Au final, la macro de substitution transformera 3 requêtes de base en 6 :
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Exemples de formats de sortie
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet de sortir les résultats sous forme libre ainsi que structurée, par exemple CSV ou JSON.
Exportation de la liste des suggestions
Format du résultat :
$results.format('$suggest\n')
Exemple de résultat :
buy essays online
buy essay cheap
buy essay uk
buy essays online no plagiarism
buy essay papers
buy essay online reviews
buy essays reddit
buy essay friend
Sortie de la requête, des suggestions par requête + type de suggestion
Format du résultat :
$query:\n$results.format('$suggest - $type\n')
Exemple de résultat :
cheap essay:
cheap essay writing service - 1
cheap essay writing service uk - 1
cheap essay writing service canada - 1
cheap essay writing 24 - 1
cheap essays online - 1
cheap essay writing service reddit - 1
cheap essay writing service australia - 1
cheap essay writing service review - 1
buy essay:
buy essay online - 1
buy essay cheap - 1
buy essay uk - 1
buy essay papers - 1
buy essay online reviews - 1
buy essays reddit - 1
buy essay friend - 1
buy essay online uk - 1
Sortie dans un tableau CSV
L'utilitaire intégré $tools.CSVLine permet de créer des documents tabulaires corrects, prêts pour l'importation dans Excel ou Google Sheets.
Format général du résultat :
[% FOREACH i IN p1.results;
tools.CSVline(i.suggest);
END %]
Nom du fichier :
$datefile.format().csv
Texte initial :
Suggestions
Dans le Format général des résultats, le moteur de gabarit Template Toolkit est utilisé pour afficher les éléments du tableau $results dans une boucle FOREACH.
Dans le nom du fichier de résultats, il suffit de changer l'extension du fichier en csv.
Pour que l'option "Prepend text" soit disponible dans l'Éditeur de tâches, il faut activer "More options". Dans "Prepend text", nous inscrivons les noms des colonnes séparés par des virgules et nous laissons la deuxième ligne vide.
Concurrence des mots-clés
Sauvegarde au format SQL
Format du résultat :
[% FOREACH results; "INSERT INTO serp VALUES('" _ query _ "', '"; suggest _ "', '"; type _ "')\n"; END %]
Exemple de résultat :
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service uk', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service canada', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing 24', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay online', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay cheap', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay uk', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay papers', '1')
...
Dump des résultats en JSON
Format de sortie general:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.suggests = [];
FOREACH item IN p1.results;
obj.suggests.push(item.suggest);
END;
obj.json %]
Texte initial:
[
Texte final:
]
Exemple de résultat :
[{"suggests":["buy essay online","buy essay cheap","buy essay uk","buy essays online no plagiarism","buy essay papers","buy essay online reviews","buy essays reddit","buy essay friend"],"totalcount":8}]
Pour que les options "Prepend text" et "Append text" soient disponibles dans l'Éditeur de tâches, il faut activer "More options".
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte. Dans cette section, nous avons listé les cas les plus populaires pour le scraper SE::Google::Suggest.
Option Parser jusqu'au niveau (Parse to level)
Cette option indique au scraper d'ajouter les résultats obtenus dans la file des requêtes en profondeur jusqu'au niveau indiqué, par exemple :
- Si le 1er niveau est indiqué, le scraper ajoutera aux requêtes tous les résultats obtenus à partir de la requête initiale.
- Si le 2ème niveau est indiqué, le scraper ajoutera aux requêtes tous les résultats obtenus à partir de la requête initiale + tous les résultats obtenus à partir des requêtes du 1er niveau.
- et ainsi de suite.
En termes simples, il s'agit de la substitution des résultats obtenus dans la file des requêtes, ce qui permet de collecter plus de résultats. Comme il y aura probablement des doublons dans les résultats, il est recommandé d'activer l'unicité des requêtes (Unique queries) pour que le scraper ne fasse pas de travail inutile (ne collecte pas la même chose).
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE1v2zAM/SsGkcMGZEF72MW3NFiGDlmd1c0pyEGIaVerLHmSnDQw/N9HKo7t
bEFvpvj4+PFIN+CFe3Nriw69g3jbQBW+IYb0Wxx/N6ZQGMdpXRTofPQlWgvrMPIm
UnhAFeG7KCuFMIWKHZY5trdCCZFhLmpFXw34U4WUwlReGu3IJzMyA8WKeenlIFRN
mPu7doQ/oLUyw0tAZkoh9QCG4/E4K0Li2d6U8EFoMcoBm/Qj6OsYihra3W4KNCXq
xS2NLQVPa1Ldz7rR9c5UHPDFkDOXYUSXGLKeRMlsk0x4ZO8sD0SfPs/8OzOILJM8
G6HOGXiuQ9aNln9CNc5bqQvCk2kluqWlrmPwGEj48XSpcAuTYAPR1CH+1zkGYm9r
nIKjapeCasl6Ry6UI4/0aIU3Nunkihsweq5UkGqABfqHWqqM9mCeU9BjF3gbkvzH
0fYdjlORHEdLNfQswXpIfg5RmVmZghrXhtpWspSebLcwtWZt7ujxDbHqx/bEsNJY
7NN0zF12uocKNWs/qDavhqerNq6UuX7cG53LIun26YKs9QsdXaIXhk+H+9K1UqSK
w+dhQ+auk4GNocB/gxchBd/C5brAG6Pcj/RcamUlbeBXLrCkSY6zdpR7odTmeTX2
wLBRfFQ87gidEydguMfC0B5RM+2uv/v+F9LcvP64aUmm3259RnNPjKU3Go4jDejS
27/f2JZm
Filtrage des résultats (utilisation de mots-clés négatifs)
En utilisant des mots-clés négatifs, il est possible de supprimer immédiatement les résultats dont vous n'avez pas besoin. De même, en utilisant un filtre, vous pouvez ne conserver que les résultats qui contiennent les mots souhaités.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE1vGjEQ/SvIQkojpSgcetkbQaFqRUMa4EQ4WOywceO1tx4vFBH+e2e83g9a
xG1n5r2ZNx/ro/AS3/HZAYJHkayOogjfIhHzxyT5am2mIUnmZZYB+t7n3hKhlytT
Ym9vXYriThTSITgmry5xCJHCVpaavo7CHwqg3Lbwyhpmq5TMkGIKO9Dk2UldEmZ4
f+rgd+CcSqEmpDaXyrRgsd/vB1koPNjYXFyhZp0aYjm/Bn3rQsF0oVulPTgK07S4
tWQVv7gnjJ2v7yJuUZEcGOtz6TdvnbwO0lT5D6U1ZFJ/YCGNQgZUMyLENYlb6yhh
FNEm7Ucxgyr+6aYfNb2+mptbcVqva+U4CQjmFMNBXH4TnMsdLGzVL7TuCVlPMg+V
UumBo3Wp24H/wxkkt0UNSF1V4ANpqy6N+h2UonfKZIQn0ynAiaP1JcJDSMLOQ61w
JfrB5rmWgf+z4ojEuxJo7qR2IklL2gS2UiNFFC1Beutm8e6So7BmpHW4uRYW0j+U
Sqd00KMtkb5F4mXI7L8cp6bDbila2t6RhlpoMB5mP1pSaqc2o76Npa61ypUnG8e2
NLyae3K+AxTN1J4YllsHTZUoLxanH7oAwwfSLm1UtK6zLs4Wc+7cWLNV2SweXY0s
zYJejZkZ27zQwG2ZUmtaCsJLeyAjjFtgoxX4L3kcSvA/Xb8Swlur8fu8klo4RQf4
hQXmNMhu1ZhyI7Vevky7EdEeFD8OPO4eIMqDYLiHzNIZUTOndfN+NW/g8eIrlhxP
tKZf+FyhuSfGko+Gg+FHHZ7+As4s2Yc=
Voir aussi : Filtres de résultats
Paramètres possibles
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Client | Chrome omnibox | Choix de la source à utiliser pour collecter les suggestions (Search page / Chrome omnibox) |
| Follow suggests | Human | Choix du type de suggestions à substituer dans les requêtes lors de l'utilisation de Parser to level (All / Synthetic / Human) |
| Google domain | www.google.com | Choix du domaine |
| Search from country | Global | Choix du pays d'où s'effectue la recherche |
| Interface language | English | Choix de la langue de l'interface |
| Remove HTML tags | ☑ | Suppression des balises HTML |