Shop::Wildberries::ProductInfo - scraper de page produit Wildberries
Présentation du scraper
En utilisant le scraper de produits Wildberries, vous pouvez obtenir des données sur les produits à partir d'une liste de liens vers les pages de ces produits.
La fonctionnalité d'A-Parser permet de sauvegarder les paramètres de collecte de données pour une utilisation ultérieure (présélections), de définir un calendrier de collecte de données et bien plus encore. Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, l'itération de combinaisons alphanumériques et de listes pour obtenir le maximum de résultats possible.
Données collectées
Principales
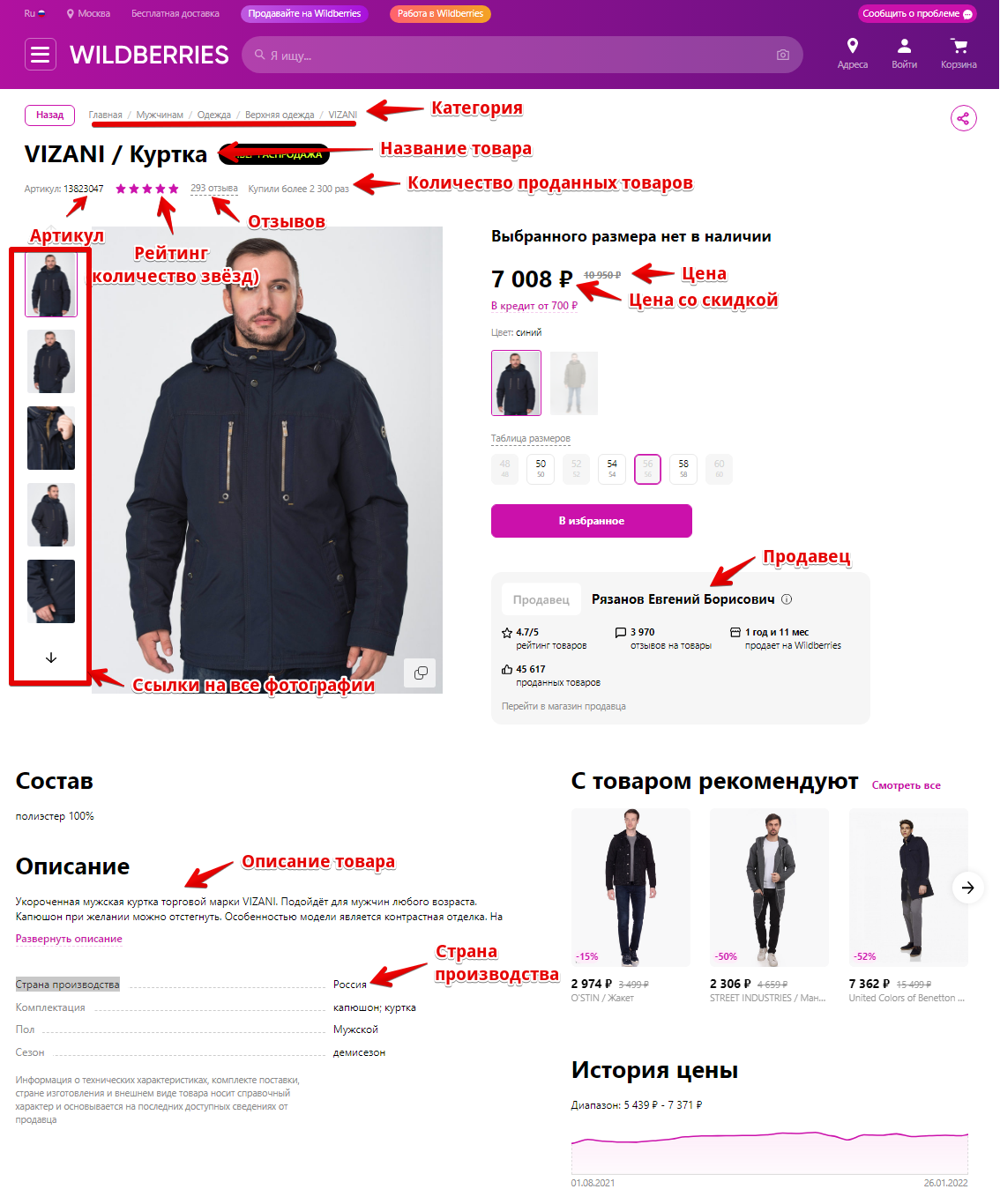
- Nom du produit (
title) - Chemin de la catégorie sur WB (
category) - Marque (
brand) - Lien vers la marque/catégorie sur WB (
brandSubUrl) - Référence, nm ID (
sku) - Description (
description) - Pays de fabrication (
country) - Couleurs, séparées par
;(colors)
Prix et stock
- Ancien prix, barré sur le site (
price) — hors livraison - Prix remisé (
discountPrice) — hors livraison - Livraison séparée (
logisticsPrice) ; si aucune —0 - Prix avec WB Wallet (
walletPrice) — uniquement si Currency = RUB ; remise d'environ 2% surdiscountPrice, hors livraison ; pas pour tous les produits — dans ce cas0ou vide - Stock restant (
qty) — n'est pas le nombre de ventes
Calculez le prix final « comme sur le site » vous-même dans le gabarit, par exemple discountPrice + logisticsPrice (sur la vitrine WB, le montant peut dépendre du point de retrait, le scraper renvoie les composants séparément).
Vendeur
- Nom du vendeur (
seller) - Lien vers le vendeur (
sellerUrl) - Nom légal de l'entreprise (
sellerLegalName) - INN (
inn) - OGRN (
ogrn) - Marque commerciale (
trademark) - Adresse légale (
legalAddress)
Avis
- Nombre d'avis (
comments) - Note du produit (
rating)
Tableaux
- Photos (
photos, champurl) — liens vers les images du produit - Historique des prix (
prices, champsdate,price) — les valeurs des champs peuvent être absentes ou varier en quantité, ce qui signifie que différents produits peuvent avoir un nombre différent de dates et de prix dans l'historique, et pour certains produits, cette information peut ne pas être présente du tout - Tags de recherche WB (
tags, champtag) — « Recherché avec ce produit »
Cas d'utilisation
- Suivi de la dynamique des prix des produits
- Évaluation des produits par note, avis et disponibilité
- Collecte de toutes les images des produits
Requêtes
Vous devez spécifier des liens vers les produits comme requêtes, par exemple :
https://www.wildberries.ru/catalog/13823047/detail.aspx
https://www.wildberries.ru/catalog/12622014/detail.aspx?targetUrl=MI
https://www.wildberries.ru/catalog/4068082/detail.aspx?targetUrl=MI
https://www.wildberries.ru/catalog/2776868/detail.aspx?targetUrl=GP
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées de substitution de requêtes.
Par exemple, nous voulons que le scraper insère automatiquement et successivement le numéro d'article dans le lien du produit de 1 à 100 000. Pour cela, on peut appliquer la macro {num:START:END}.
Comme requête, indiquons le lien vers n'importe quel produit et à la place de l'article, inscrivons la macro :
https://www.wildberries.ru/catalog/{num:1:100000}/detail.aspx
Cette méthode permet de collecter les données des produits Wildberries très facilement et automatiquement, même sans connaître leurs articles. A-Parser insérera lui-même le numéro dans l'ordre, se rendra sur la page et collectera les données si elles existent.
Paramètres possibles
| Paramètre | Valeur par défaut | Description |
|---|---|---|
| Currency | RUB | Devise des prix dans les résultats : RUB, BYN, KZT, KGS, AMD, UZS, TJS, ETB, GEL. La variable walletPrice n'est renseignée que pour le RUB |
| Address | Adresse du point de retrait ; avec les coordonnées, elle définit la région et influence les prix | |
| Longitude | Longitude du point de retrait | |
| Latitude | Latitude du point de retrait | |
| Max concurrent browser pages | 5 | Le nombre de pages Chrome que le scraper peut ouvrir simultanément. À augmenter avec prudence en cas de nombre élevé de threads — la charge sur la mémoire et le CPU augmente |
| Chrome Headless | ☑ | Lancement du navigateur en arrière-plan (sans fenêtre visible). Si la vérification sur le site échoue ou si un débogage est nécessaire — décochez la case |
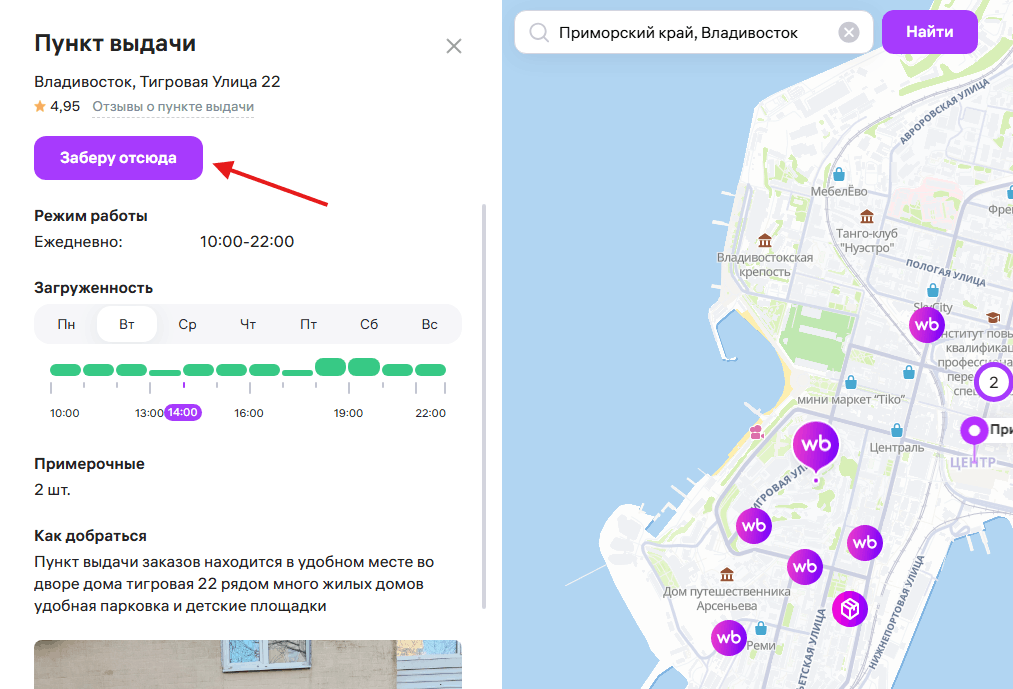
Par défaut, Wildberries affiche les résultats pour Moscou. Dans le scraper, il est possible de définir un point de retrait et la liste des résultats sera liée à un emplacement spécifique. Pour ce faire, vous devez redéfinir 3 paramètres : Address, Longitude et Latitude. Vous pouvez obtenir les valeurs nécessaires pour ces paramètres dans le navigateur :
1. Choisissez le point de retrait souhaité, après avoir ouvert les Outils de développement (dans Chrome, touche F12)
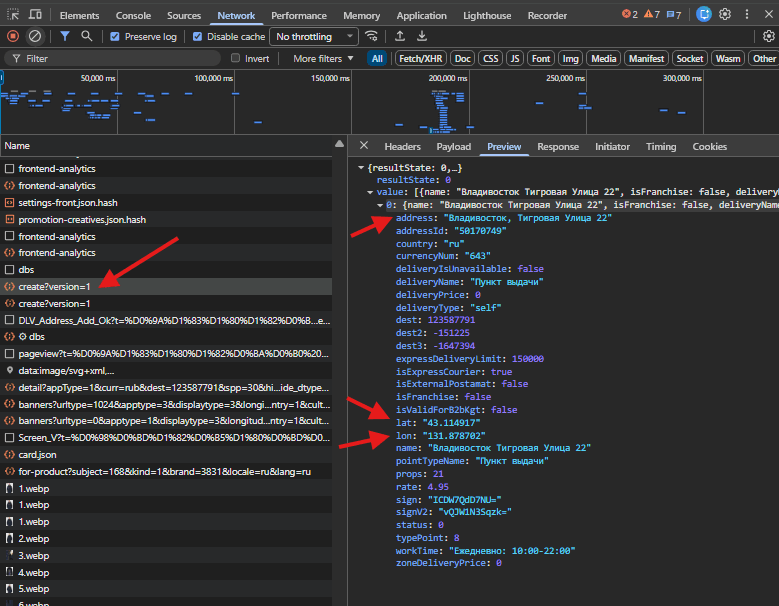
2. Dans l'onglet « Réseau », recherchez la requête create?version=1 et copiez les données dans les paramètres du scraper
Après avoir choisi le point de retrait, ouvrez l'onglet Réseau (dans Chrome en anglais — Network). Recherchez la requête create?version=1, dans la réponse (Preview), copiez address, lat et lon dans les champs Address, Latitude et Longitude du scraper respectivement.