HTML::EmailExtractor - Collecte de données d'adresses email à partir de pages web
Présentation du scraper
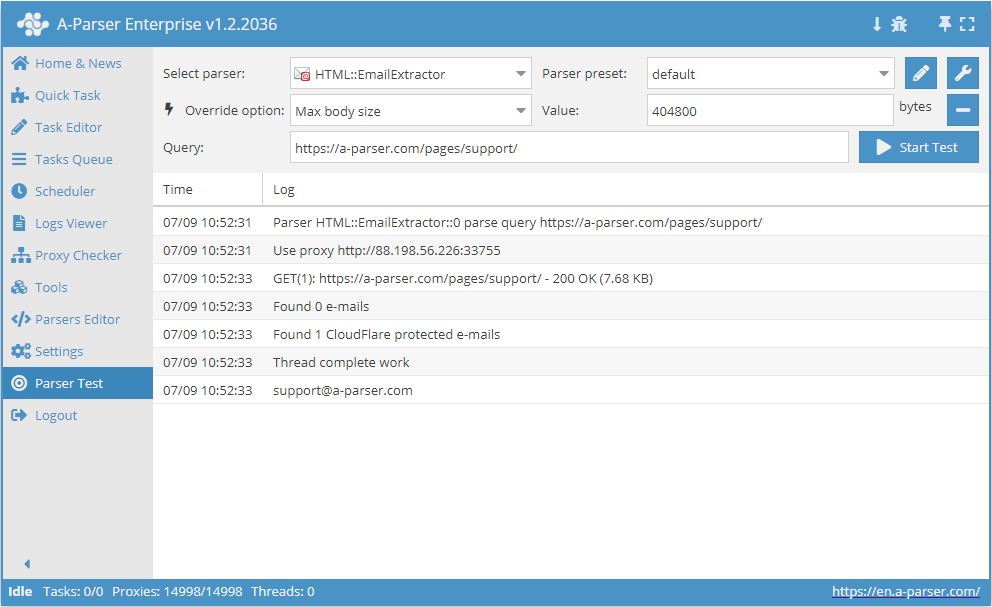
 HTML::EmailExtractor collecte les adresses e-mail à partir des pages spécifiées. Supporte la navigation sur les pages internes du site jusqu'à la profondeur spécifiée, ce qui permet de parcourir toutes les pages du site en collectant les liens internes et externes. Le scraper d'emails dispose d'outils intégrés pour contourner la protection CloudFlare et offre également la possibilité de choisir Chrome comme moteur pour collecter les emails des pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse allant jusqu'à 250 requêtes par minute – soit 15 000 liens par heure.
HTML::EmailExtractor collecte les adresses e-mail à partir des pages spécifiées. Supporte la navigation sur les pages internes du site jusqu'à la profondeur spécifiée, ce qui permet de parcourir toutes les pages du site en collectant les liens internes et externes. Le scraper d'emails dispose d'outils intégrés pour contourner la protection CloudFlare et offre également la possibilité de choisir Chrome comme moteur pour collecter les emails des pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse allant jusqu'à 250 requêtes par minute – soit 15 000 liens par heure.Cas d'utilisation du scraper
Collecte d'emails à partir d'un site avec exploration des pages jusqu'à la limite spécifiée
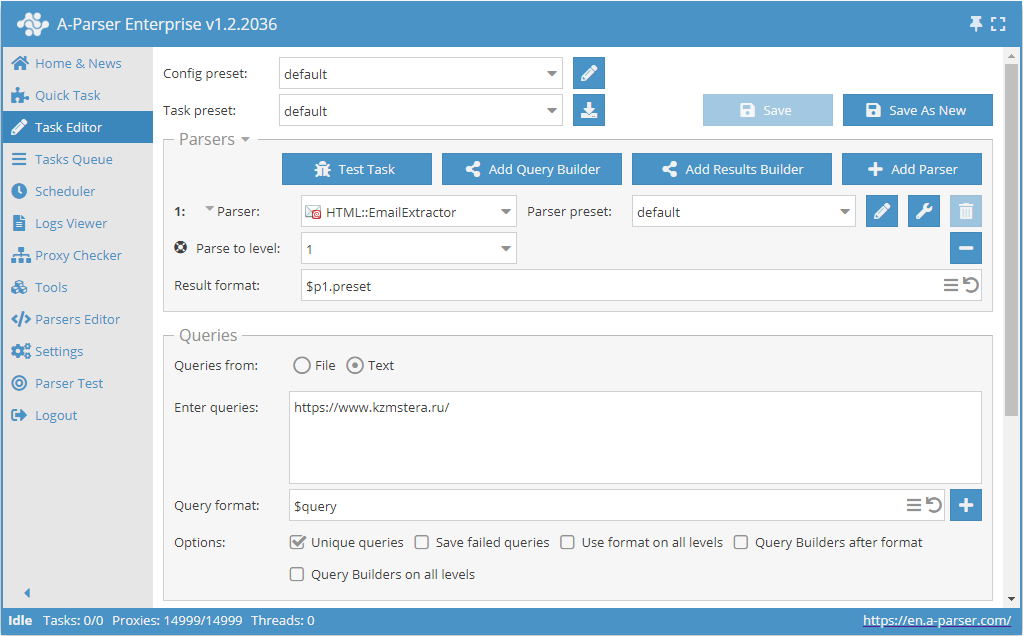
- Ajouter l'option Parse to level (Parser jusqu'au niveau / Parse to level), sélectionner la valeur souhaitée (limite) dans la liste.
- Dans la section Queries (Requêtes), cocher l'option
Unique queries. - Dans la section Results (Résultats), cocher l'option
Unique string. - Indiquer comme requête le lien du site à partir duquel vous souhaitez collecter les emails.
Télécharger l'exemple
Comment importer un exemple dans A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
astuce
Collecte d'emails à partir d'une base de sites avec exploration de chaque site jusqu'à la limite spécifiée
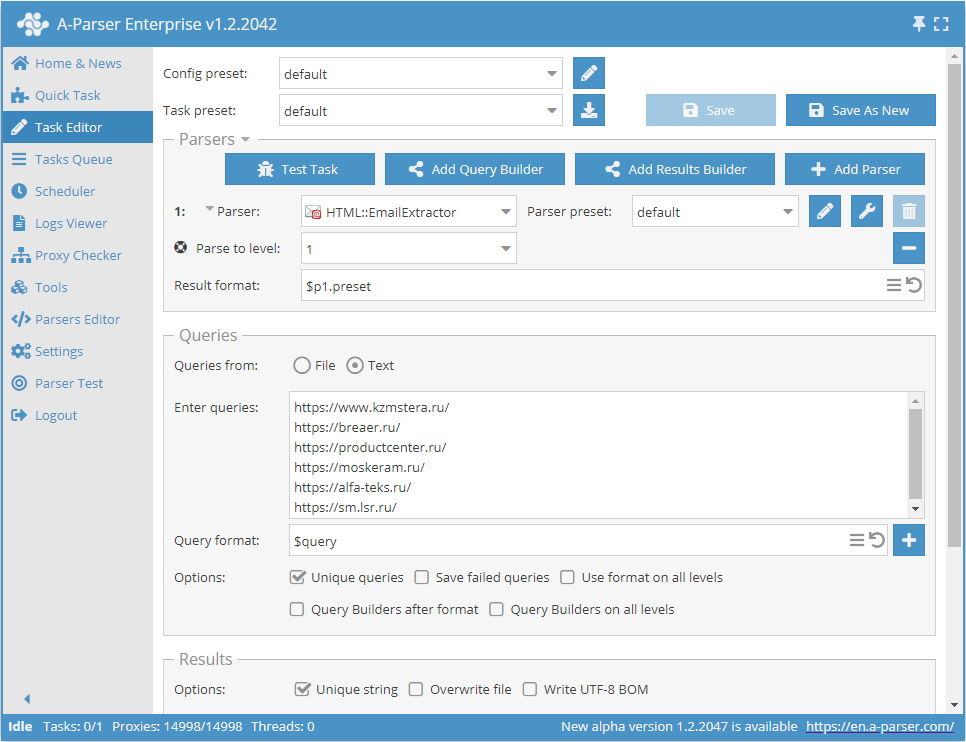
- Ajouter l'option Parse to level (Parser jusqu'au niveau / Parse to level), sélectionner la valeur souhaitée (limite) dans la liste.
- Dans la section Queries (Requêtes), cocher l'option
Unique queries. - Dans la section Results (Résultats), cocher l'option
Unique string. - Indiquer comme requête les liens des sites à partir desquels vous souhaitez collecter les emails, ou dans Queries from (Requêtes depuis), sélectionner
Fileet charger le fichier de requêtes avec la base de sites.
Télécharger l'exemple
Comment importer un exemple dans A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
astuce
Collecte d'emails à partir d'une base de liens
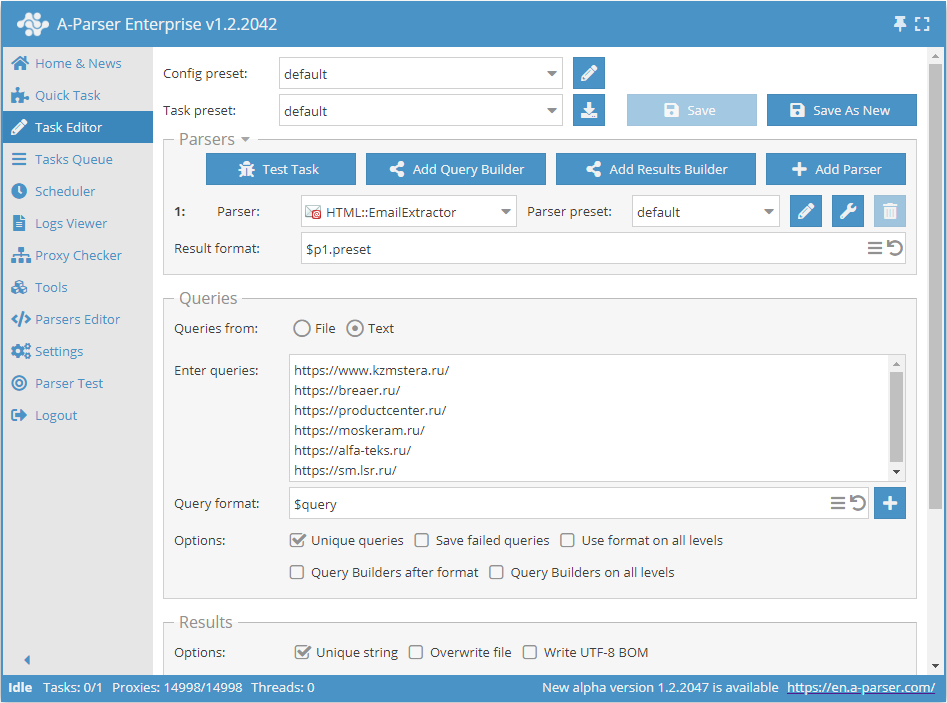
- Dans la section Queries (Requêtes), cocher l'option
Unique queries. - Dans la section Results (Résultats), cocher l'option
Unique string. - Indiquer comme requête les liens à partir desquels vous souhaitez collecter les emails, ou dans Queries from (Requêtes depuis), sélectionner
Fileet charger le fichier de requêtes avec la base de liens.
Télécharger l'exemple
Comment importer un exemple dans A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
astuce
Données collectées
- Adresses e-mail
- Nombre total d'adresses sur la page
- Tableau de toutes les pages collectées (utilisé avec l'option Use Pages)
Fonctionnalités
- Collecte de données multipages (navigation entre les pages)
- Navigation sur les pages internes du site jusqu'à la profondeur spécifiée (option Parse to level) – permet de parcourir toutes les pages du site en collectant les liens internes et externes
- Détection des liens follow pour les liens
- Limite de navigation entre les pages (option Follow links limit)
- Possibilité de considérer les sous-domaines comme des pages internes du site
- Supporte les compressions gzip/deflate/brotli
- Détection et conversion de l'encodage des sites en UTF-8
- Contournement de la protection CloudFlare
- Choix du moteur (HTTP ou Chrome)
- Prise en charge de toutes les fonctionnalités de
 HTML::LinkExtractor
HTML::LinkExtractor
Cas d'utilisation
- Collecte d'adresses email
- Affichage du nombre d'adresses e-mail
Requêtes
Les requêtes doivent être des liens vers des pages, par exemple :
https://a-parser.com/pages/support/
Variantes d'affichage des résultats
A-Parser supporte un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet de sortir les résultats sous n'importe quelle forme, ainsi que de manière structurée, par exemple en CSV ou JSON
Affichage du nombre d'adresses email
Format du résultat :
$mailcount
Exemple de résultat :
4
Paramètres possibles
note
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Good status | All | Choix de la réponse du serveur qui sera considérée comme réussie. Si lors de la collecte une autre réponse est reçue du serveur, la requête sera répétée avec un autre proxy |
| Good code RegEx | Possibilité de spécifier une expression régulière pour vérifier le code de réponse | |
| Ban Proxy Code RegEx | Possibilité de bannir le proxy temporairement (Proxy ban time) sur la base du code de réponse du serveur | |
| Method | GET | Méthode de requête |
| POST body | Contenu à transmettre au serveur lors de l'utilisation de la méthode POST. Supporte les variables $query – URL de la requête, $query.orig – requête d'origine et $pagenum - numéro de page lors de l'utilisation de l'option Use Pages. | |
| Cookies | Possibilité de spécifier des cookies pour la requête. | |
| User agent | _Le user-agent de la version actuelle de Chrome est inséré automatiquement_ | En-tête User-Agent lors de la requête des pages |
| Additional headers | Possibilité de spécifier des en-têtes de requête personnalisés avec le support des fonctionnalités du moteur de gabarit et l'utilisation de variables du constructeur de requêtes | |
| Read only headers | ☐ | Lire uniquement les en-têtes. Dans certains cas, cela permet d'économiser du trafic s'il n'est pas nécessaire de traiter le contenu |
| Detect charset on content | ☐ | Reconnaître l'encodage sur la base du contenu de la page |
| Emulate browser headers | ☐ | Émuler les en-têtes du navigateur |
| Max redirects count | 0 | Nombre maximum de redirections que le scraper suivra |
| Follow common redirects | ☑ | Permet d'effectuer des redirections http <-> https et www.domain <-> domain au sein d'un même domaine en contournant la limite Max redirects count |
| Max cookies count | 16 | Nombre maximum de cookies à conserver |
| Engine | HTTP (Fast, JavaScript Disabled) | Permet de choisir le moteur HTTP (plus rapide, sans JavaScript) ou Chrome (plus lent, JavaScript activé) |
| Chrome Headless | ☐ | Si l'option est activée, le navigateur ne sera pas affiché |
| Chrome DevTools | ☑ | Permet d'utiliser les outils de débogage de Chromium |
| Chrome Log Proxy connections | ☑ | Si l'option est activée, les informations sur les connexions chrome seront affichées dans le log |
| Chrome Wait Until | networkidle2 | Définit quand la page est considérée comme chargée. En savoir plus sur les valeurs. |
| Use HTTP/2 transport | ☐ | Définit s'il faut utiliser HTTP/2 au lieu de HTTP/1.1. Par exemple, Google et Majestic bannissent immédiatement si HTTP/1.1 est utilisé. |
| Don't verify TLS certs | ☐ | Désactivation de la validation des certificats TLS |
| Randomize TLS Fingerprint | ☐ | Cette option permet de contourner le bannissement des sites par empreinte TLS |
| Bypass CloudFlare | ☑ | Contournement automatique de la vérification CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Contournement de CF via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Nombre max. de pages lors du contournement de CF via Chrome |
| Subdomains are internal | ☐ | Considérer ou non les sous-domaines comme des liens internes |
| Follow links | Internal only | Quels liens suivre |
| Follow links limit | 0 | Limite de Follow links, s'applique à chaque domaine unique |
| Skip comment blocks | ☐ | Ignorer ou non les blocs de commentaires |
| Search Cloudflare protected e-mails | ☑ | Collecter ou non les e-mails protégés par Cloudflare. |
| Skip non-HTML blocks | ☑ | Ne pas collecter les adresses e-mail dans les balises (script, style, comment, etc.). |
| Skip meta tags | ☐ | Ne pas collecter les adresses e-mail dans les balises meta |
| Search URL encoded e-mails | ☐ | Collecte des e-mails encodés en URL |