HTML::LinkExtractor - Scraper de liens externes et internes d'un site spécifié
Présentation du scraper
 HTML::LinkExtractor – scraper de liens externes et internes d'un site spécifié. Supporte la collecte multipages et la navigation à travers les pages internes du site jusqu'à la profondeur indiquée, ce qui permet de parcourir toutes les pages du site en collectant les liens internes et externes. Possède des outils intégrés de contournement de protection CloudFlare ainsi que la possibilité de choisir Chrome comme moteur pour la collecte d'e-mails sur les pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse de 2000 requêtes par minute – soit 120 000 liens par heure.
HTML::LinkExtractor – scraper de liens externes et internes d'un site spécifié. Supporte la collecte multipages et la navigation à travers les pages internes du site jusqu'à la profondeur indiquée, ce qui permet de parcourir toutes les pages du site en collectant les liens internes et externes. Possède des outils intégrés de contournement de protection CloudFlare ainsi que la possibilité de choisir Chrome comme moteur pour la collecte d'e-mails sur les pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse de 2000 requêtes par minute – soit 120 000 liens par heure.Cas d'utilisation du scraper
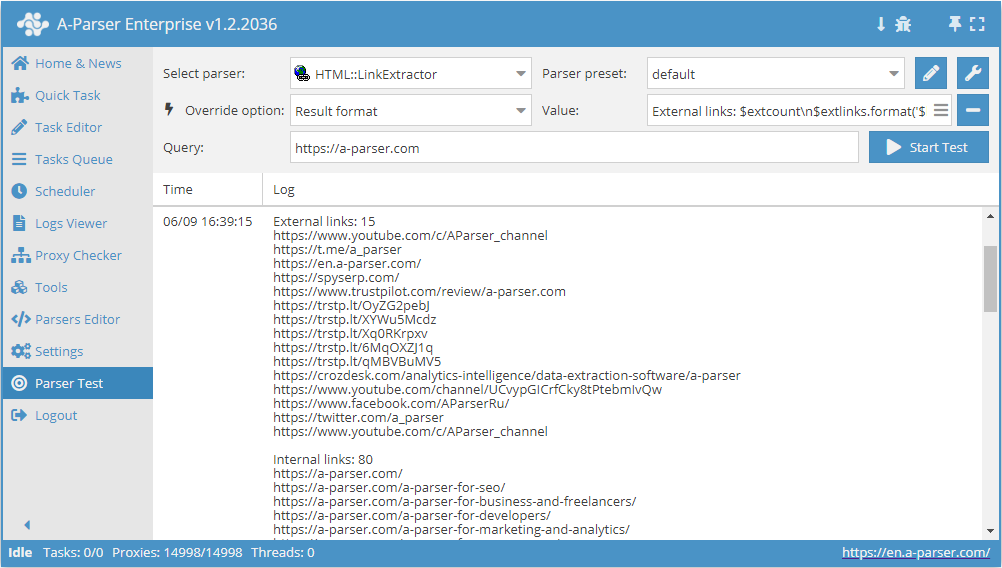
Collecte de tous les liens externes d'un site
- Ajouter l'option Parse to level (Parser jusqu'au niveau), dans la liste choisir la valeur
10(navigation à travers les pages adjacentes jusqu'au 10ème niveau). - Ajouter l'option Result format, indiquer comme valeur
$extlinks.format('$link\n')(affichage des liens externes). - Dans la section Queries (Requêtes), cocher l'option
Unique queries. - Dans la section Results (Résultats), cocher l'option
Unique string. - Indiquer comme requête le lien du site dont vous souhaitez extraire les liens externes.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
astuce
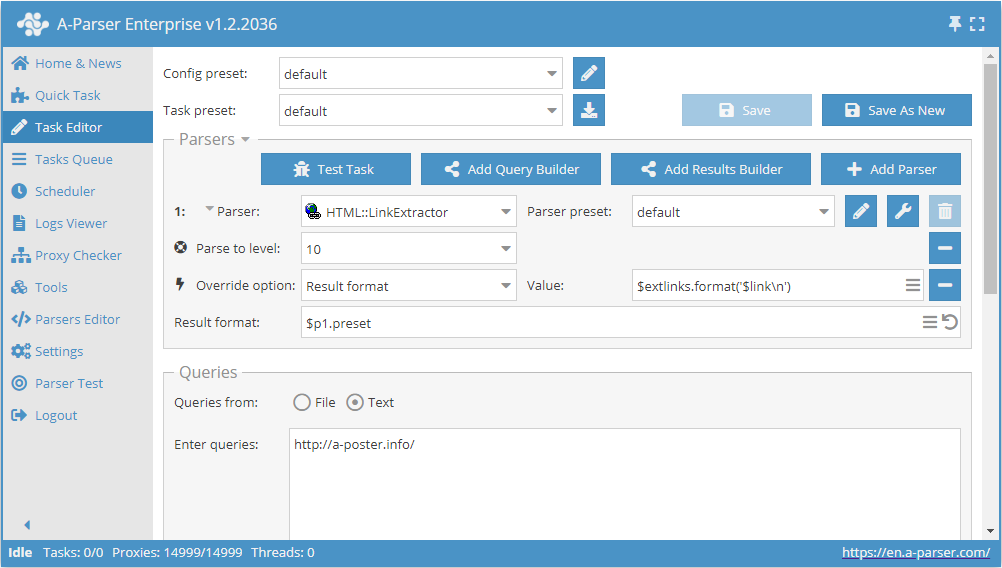
Collecte de tous les liens internes d'un site
Identique au premier cas, mais à l'étape 2, il faut indiquer comme valeur $intlinks.format('$link\n') (affichage des liens internes).
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Suivre uniquement les liens ne contenant pas le mot forum
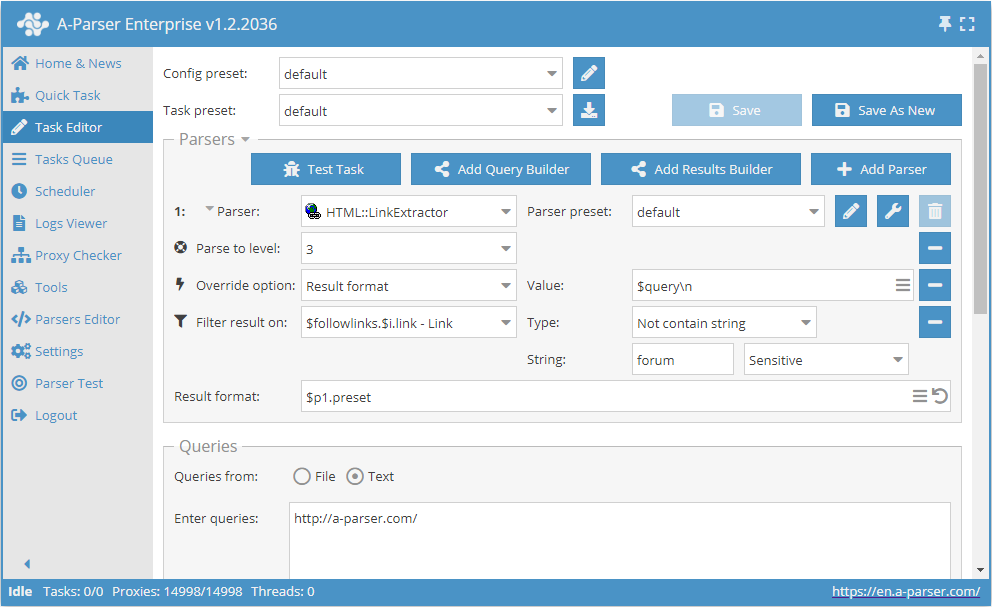
- Ajouter l'option Parse to level (Parser jusqu'au niveau), dans la liste choisir la valeur
3(navigation à travers les pages adjacentes jusqu'au 3ème niveau). - Ajouter l'option Result format, indiquer comme valeur
$query. - Ajouter un filtre. Filtrer par
$followlinks.$i.link - Link, choisir le typeNe contient pas la chaîne, et indiquerforumcomme chaîne. - Dans la section Queries (Requêtes), cocher l'option
Unique queries. - Dans la section Results (Résultats), cocher l'option
Unique string. - Indiquer comme requête le lien du site dont vous souhaitez extraire les liens.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
astuce
Données collectées
- Nombre de liens externes
- Nombre de liens internes
- Liens externes :
- les liens eux-mêmes
- les ancres
- les ancres nettoyées des balises HTML
- le paramètre nofollow
- la balise
<a>complète
- Liens internes :
- les liens eux-mêmes
- les ancres
- les ancres nettoyées des balises HTML
- le paramètre nofollow
- la balise
<a>complète
- Tableau de toutes les pages collectées (utilisé avec l'option Use Pages)
Fonctionnalités
- Collecte de données multipages (navigation entre les pages)
- Navigation à travers les pages internes du site jusqu'à la profondeur indiquée (option Parse to level) – permet de parcourir toutes les pages du site en collectant les liens internes et externes
- Limite de navigation entre les pages (option Follow links limit)
- Nettoyage automatique des ancres des balises HTML
- Détection du nofollow pour chaque lien
- Possibilité de compter les sous-domaines comme des pages internes du site
- Supporte les compressions gzip/deflate/brotli
- Détection et conversion des encodages des sites en UTF-8
- Contournement de la protection CloudFlare
- Choix du moteur (HTTP ou Chrome)
Cas d'utilisation
- Obtention d'un plan complet du site (sauvegarde de tous les liens internes)
- Obtention de tous les liens externes d'un site
- Vérification d'un lien retour vers son propre site
Requêtes
Comme requêtes, il est nécessaire d'indiquer les liens vers les pages à partir desquelles les liens doivent être collectés, ou un point d'entrée (par exemple, la page d'accueil du site), lorsque l'option Parse to level est utilisée :
https://lenta.ru/
https://a-parser.com/wiki/index/
Exemples de sortie de résultats
A-Parser supporte un formatage flexible des résultats grâce au moteur de modèles intégré Template Toolkit, ce qui lui permet de sortir les résultats sous n'importe quelle forme, y compris structurée comme CSV ou JSON
Affichage des liens externes et internes avec leur nombre
Format du résultat :
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Exemple de résultat :
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Paramètres possibles
note
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Good status | All | Choix de la réponse du serveur qui sera considérée comme réussie. Si une autre réponse est reçue lors de la collecte, la requête sera répétée avec un autre proxy |
| Good code RegEx | Possibilité d'indiquer une expression régulière pour vérifier le code de réponse | |
| Ban Proxy Code RegEx | Possibilité de bannir le proxy temporairement (Proxy ban time) sur la base du code de réponse du serveur | |
| Method | GET | Méthode de requête |
| POST body | Contenu à transmettre au serveur lors de l'utilisation de la méthode POST. Supporte les variables $query – URL de la requête, $query.orig – requête d'origine et $pagenum - numéro de page lors de l'utilisation de l'option Use Pages. | |
| Cookies | Possibilité d'indiquer des cookies pour la requête. | |
| User agent | _Le user-agent de la version actuelle de Chrome est inséré automatiquement_ | En-tête User-Agent lors de la requête des pages |
| Additional headers | Possibilité d'indiquer des en-têtes de requête personnalisés avec support des fonctionnalités du moteur de modèles et utilisation des variables du constructeur de requêtes | |
| Read only headers | ☐ | Lire uniquement les en-têtes. Permet dans certains cas d'économiser du trafic s'il n'est pas nécessaire de traiter le contenu |
| Detect charset on content | ☐ | Reconnaître l'encodage sur la base du contenu de la page |
| Emulate browser headers | ☐ | Émuler les en-têtes du navigateur |
| Max redirects count | 0 | Nombre maximum de redirections que le scraper suivra |
| Follow common redirects | ☑ | Permet d'effectuer des redirections http <-> https et www.domain <-> domain au sein d'un même domaine en contournant la limite Max redirects count |
| Max cookies count | 16 | Nombre maximum de cookies à sauvegarder |
| Engine | HTTP (Fast, JavaScript Disabled) | Permet de choisir le moteur HTTP (plus rapide, sans JavaScript) ou Chrome (plus lent, JavaScript activé) |
| Chrome Headless | ☐ | Si l'option est activée, le navigateur ne sera pas affiché |
| Chrome DevTools | ☑ | Permet d'utiliser les outils de débogage de Chromium |
| Chrome Log Proxy connections | ☑ | Si l'option est activée, les informations sur les connexions chrome seront affichées dans le log |
| Chrome Wait Until | networkidle2 | Définit quand la page est considérée comme chargée. En savoir plus sur les valeurs. |
| Use HTTP/2 transport | ☐ | Définit s'il faut utiliser HTTP/2 au lieu de HTTP/1.1. Par exemple, Google et Majestic bannissent immédiatement si HTTP/1.1 est utilisé. |
| Don't verify TLS certs | ☐ | Désactivation de la validation des certificats TLS |
| Randomize TLS Fingerprint | ☐ | Cette option permet de contourner le bannissement des sites par empreinte TLS |
| Bypass CloudFlare | ☑ | Contournement automatique de la vérification CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Contournement de CF via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Nombre max. de pages lors du contournement de CF via Chrome |
| Subdomains are internal | ☐ | Compter les sous-domaines comme des liens internes |
| Follow links | Internal only | Quels liens suivre |
| Follow links limit | 0 | Limite de Follow links, s'applique à chaque domaine unique |
| Skip comment blocks | ☐ | Ignorer les blocs de commentaires |