HTML::TextExtractor - Collecte de données de contenu (texte) d'un site
Présentation du scraper
 HTML::TextExtractor extrait les blocs de texte de la page indiquée. Ce scraper de contenu supporte la collecte multipage (navigation par pages). Il dispose d'outils intégrés pour contourner la protection CloudFlare et permet également de choisir Chrome comme moteur pour collecter du contenu sur des pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse de 2000 requêtes par minute – soit 120 000 liens par heure.
HTML::TextExtractor extrait les blocs de texte de la page indiquée. Ce scraper de contenu supporte la collecte multipage (navigation par pages). Il dispose d'outils intégrés pour contourner la protection CloudFlare et permet également de choisir Chrome comme moteur pour collecter du contenu sur des pages dont les données sont chargées par des scripts. Capable d'atteindre une vitesse de 2000 requêtes par minute – soit 120 000 liens par heure.Cas d'utilisation du scraper
Collecte de texte via Chrome sur l'exemple de lingualeo.com
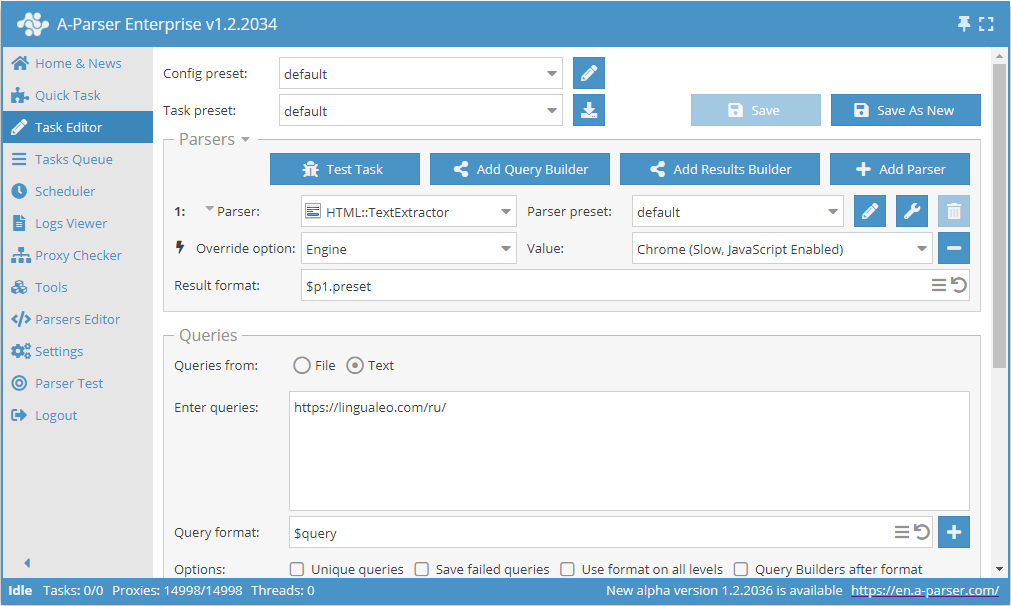
- Ajouter l'option Engine, et sélectionner le moteur
Chrome (Slow, JavaScript Enabled)dans la liste. - Indiquer comme requête le lien vers le site dont vous souhaitez extraire le texte.
Cette option peut être utile lorsque le site charge le texte principal via des scripts pendant le chargement de la page, et qu'en utilisant HTTP (Fast, JavaScript Disabled), le résultat est absent ou incomplet.
Télécharger l'exemple
Comment importer un exemple dans A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Collecte de texte avec navigation par pages sur l'exemple d'actualités
Les résultats sont enregistrés dans le répertoire aparser/results/example/textextractor dans un fichier séparé pour chaque requête. Le numéro d'ordre de la requête est utilisé comme nom de fichier.
- Ajouter l'option Check next page, et indiquer
(forum\/news\/page-\d+)"[^>]+>Suivantcomme expression régulière. - Ajouter l'option Page as new query.
- Modifier le File name (Nom du fichier) en
example/textextractor/${query.num}.txt. - Indiquer comme requête le lien vers la première page des actualités d'A-Parser :
https://a-parser.com/forum/news/.
Télécharger l'exemple
Comment importer un exemple dans A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Données collectées
- Extrait les blocs de texte de la page indiquée
- Tableau avec toutes les pages collectées (utilisé avec l'option Use Pages)
Fonctionnalités
- Collecte de texte multipage (navigation par pages)
- Nettoyage automatique du texte des balises HTML
- Possibilité de définir une longueur minimale pour le bloc de texte
- Suppression optionnelle des ancres de liens dans le texte
- Supporte les compressions gzip/deflate/brotli
- Détection et conversion de l'encodage des sites en UTF-8
- Contournement de la protection CloudFlare
- Choix du moteur (HTTP ou Chrome)
Cas d'utilisation
- Collecte de contenu textuel à partir de n'importe quel site
Requêtes
Les requêtes doivent être des liens vers les pages dont vous souhaitez extraire les blocs de texte, par exemple :
https://a-parser.com/
Exemples de sortie de résultats
A-Parser supporte un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet de sortir les résultats sous n'importe quelle forme, y compris structurée comme CSV ou JSON
Sortie par défaut
Format du résultat :
$texts.format('$text\n')
Exemple de résultat :
Bonjour, Super Équipe de Professionnels de haut niveau ! Merci pour l'opportunité d'apprendre l'espagnol, le turc et le portugais ! Je vous souhaite d'élargir encore vos possibilités ! Inspiration et Créativité ! Et s'il vous plaît, ajoutez la possibilité d'apprendre l'allemand et le français !”
J'utilise Lingualeo depuis de nombreuses années, j'ai commencé quand l'application n'existait pas encore, il n'y avait que le site) Merci aux développeurs, continuez ainsi, avec créativité et beaucoup d'amour pour votre travail)
Anglais technique pour l'informatique : dictionnaires, manuels, magazines
Apprenez les langues en ligne Apprenez l'anglais en ligne Apprenez le vietnamien en ligne Apprenez le grec en ligne Apprenez l'indonésien en ligne Apprenez l'espagnol en ligne Apprenez l'italien en ligne Apprenez le chinois en ligne Apprenez le coréen en ligne Apprenez l'allemand en ligne Apprenez le néerlandais en ligne Apprenez le polonais en ligne Apprenez le portugais en ligne Apprenez le serbe en ligne Apprenez le turc en ligne Apprenez l'ukrainien en ligne Apprenez le français en ligne Apprenez le hindi en ligne Apprenez le tchèque en ligne Apprenez le japonais en ligne
Paramètres possibles
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Min block length | 50 | Longueur minimale du bloc de texte en caractères. |
| Skip anchor text | ☐ | Indique s'il faut ignorer les ancres dans le texte. |
| Ignore tags list | Option pour spécifier les balises à ignorer. Exemple : div,span,p | |
| Good status | All | Choix de la réponse du serveur considérée comme réussie. Si une autre réponse est reçue, la requête sera répétée avec un autre proxy. |
| Good code RegEx | Possibilité de spécifier une expression régulière pour vérifier le code de réponse. | |
| Method | GET | Méthode de requête. |
| POST body | Contenu à envoyer au serveur lors de l'utilisation de la méthode POST. Supporte les variables $query – URL de la requête, $query.orig – requête initiale et $pagenum - numéro de page lors de l'utilisation de l'option Use Pages. | |
| Cookies | Possibilité de spécifier des cookies pour la requête. | |
| User agent | `_Le user-agent de la version actuelle de Chrome est inséré automatiquement_ | En-tête User-Agent lors de la requête des pages. |
| Additional headers | Possibilité de spécifier des en-têtes de requête personnalisés avec le support du moteur de gabarit et des variables du constructeur de requêtes. | |
| Read only headers | ☐ | Lire uniquement les en-têtes. Permet d'économiser du trafic dans certains cas s'il n'est pas nécessaire de traiter le contenu. |
| Detect charset on content | ☐ | Reconnaître l'encodage basé sur le contenu de la page. |
| Emulate browser headers | ☐ | Émuler les en-têtes du navigateur. |
| Max redirects count | 7 | Nombre maximum de redirections que le scraper suivra. |
| Max cookies count | 16 | Nombre maximum de cookies à conserver. |
| Bypass CloudFlare | ☑ | Contournement automatique de la vérification CloudFlare. |
| Follow common redirects | ☑ | Permet d'effectuer des redirections http <-> https et www.domain <-> domain au sein d'un même domaine en contournant la limite Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Permet de choisir le moteur HTTP (plus rapide, sans JavaScript) ou Chrome (plus lent, JavaScript activé). |
| Chrome Headless | ☐ | Si l'option est activée, le navigateur ne sera pas affiché. |
| Chrome DevTools | ☑ | Permet d'utiliser les outils de débogage de Chromium. |
| Chrome Log Proxy connections | ☑ | Si l'option est activée, les informations sur les connexions chrome seront affichées dans le log. |
| Chrome Wait Until | networkidle2 | Détermine quand la page est considérée comme chargée. Plus de détails sur les valeurs. |
| Use HTTP/2 transport | ☐ | Détermine s'il faut utiliser HTTP/2 au lieu de HTTP/1.1. Par exemple, Google et Majestic bannissent immédiatement si HTTP/1.1 est utilisé. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Contournement de CF via Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Nombre max. de pages lors du contournement de CF via Chrome. |