SE::Google - Scraper de la page de résultats de recherche Google
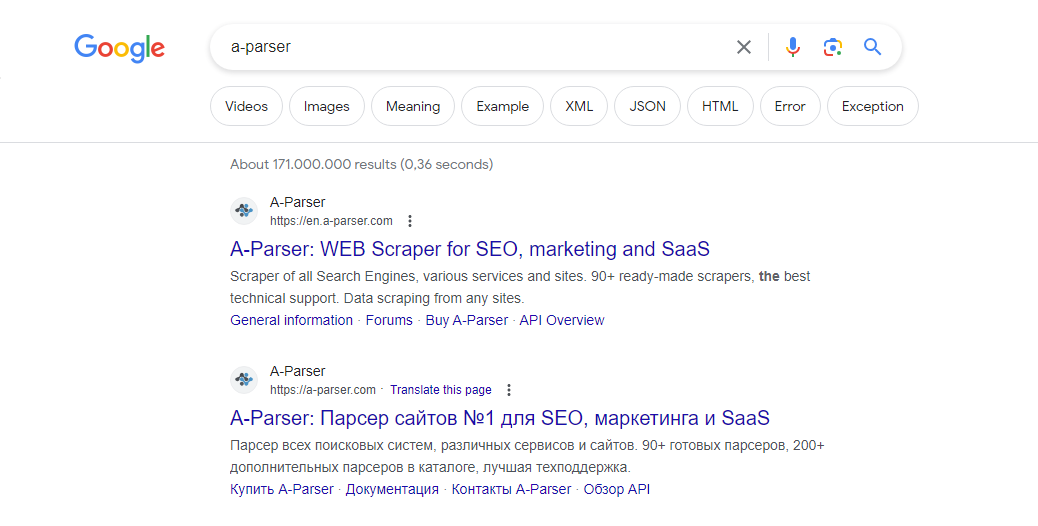
Présentation du scraper
Le scraper de la page de résultats Google (SERP) est l'un des plus demandés ; il vous permet d'obtenir d'énormes bases de liens prêts à l'emploi. Vous pouvez utiliser les requêtes telles que vous les saisissez dans Google, y compris les opérateurs de recherche (inurl, intitle, etc.).
Le scraper Google prend en charge la multiplication automatique des requêtes, vous assurant d'obtenir le nombre maximal de résultats. De plus, A-Parser peut suivre automatiquement les requêtes associées jusqu'à une profondeur spécifiée. Grâce au traitement multithread d'A-Parser, la vitesse de traitement peut atteindre 3000-7000 requêtes par minute, ce qui permet de collecter en moyenne jusqu'à 500 000 liens par minute.
Les fonctionnalités d'A-Parser permettent de sauvegarder les paramètres de collecte de données pour une utilisation ultérieure (présélections), de définir un calendrier de collecte et bien plus encore. Vous pouvez utiliser la multiplication automatique des requêtes, la substitution de sous-requêtes à partir de fichiers, la génération de combinaisons alphanumériques et de listes pour obtenir le plus grand nombre de résultats possible.
La sauvegarde des résultats est possible dans le format et la structure dont vous avez besoin, grâce au puissant moteur de gabarits intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'exporter les données dans divers formats, notamment JSON, SQL et CSV.
Cas d'utilisation du scraper
🔗 Collecte de données de domaines
Collecte de données de domaines thématiques par mot-clé depuis Google et récupération de divers paramètres pour les domaines
🔗 Collecte de données Google News
Cette présélection collecte les actualités Google pour une requête de recherche et récupère les dates de ces actualités
🔗 Vérification de l'indexation
Cette présélection vérifie l'indexation des pages d'un site dans Google en parcourant une liste de liens spécifiés
🔗 Évaluation de la concurrence
Cette présélection détermine la concurrence dans le moteur de recherche Google par mots-clés
🔗 Collecte du top 3 des résultats
Cette présélection enregistre les trois premiers snippets des résultats de recherche Google
🔗 Questions et réponses
Scraper collectant les questions et réponses de la section People Also Ask
Données collectées
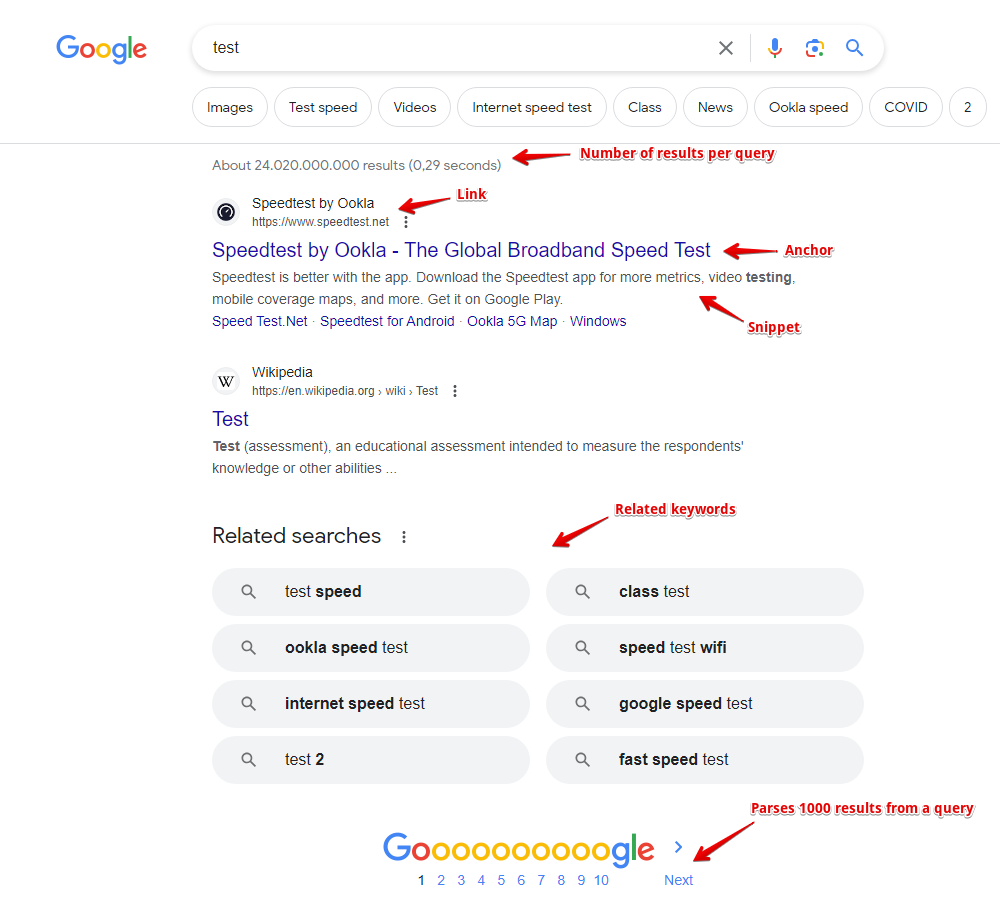
- Liens, ancres et snippets des résultats, ainsi que la date du snippet (si disponible)
- Des informations sur les indicateurs de chaque résultat sont également collectées, les indicateurs actuellement pris en charge sont : Date, AMP, Image Preview, Video, Rich snippet, Featured snippet
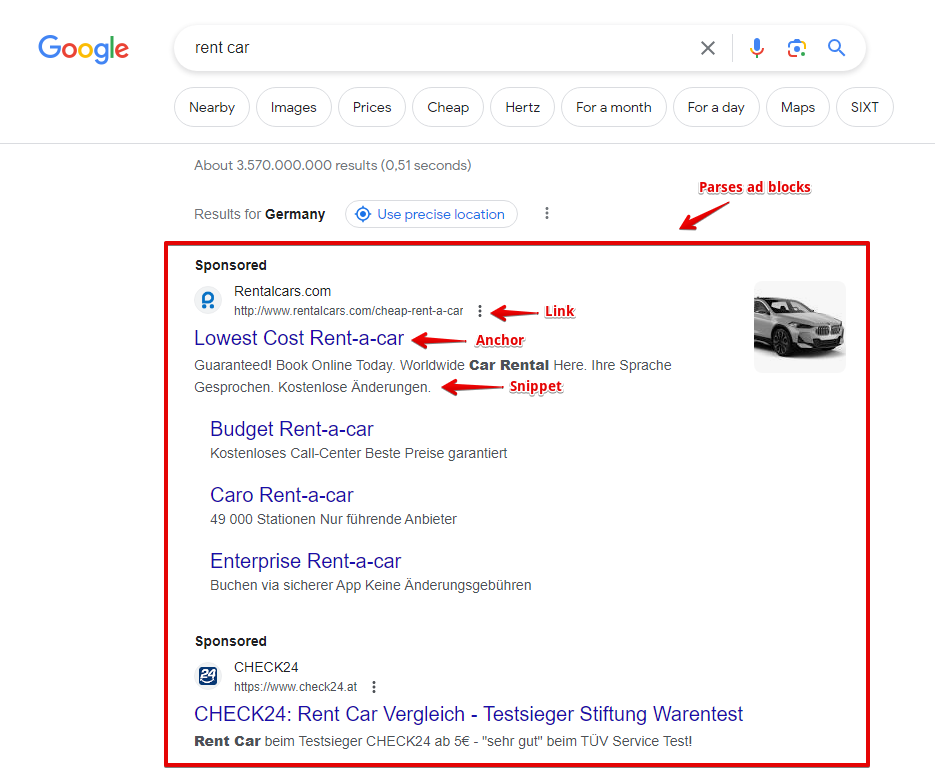
- Présence et contenu des blocs publicitaires, ainsi que leur position sur la page
- Nombre de résultats par requête (concurrence)
- Liste des mots-clés associés (Related keywords)
- Présence de blocs supplémentaires sur la page : carrousel de produits, vidéos, etc.
- Le scraper collecte également ces données supplémentaires :
- Présence d'une faute de frappe dans la requête et requête corrigée
- Géolocalisation déterminée par Google
- Présence de pages AMP
- Liste People also ask : questions, réponses, liens vers les sources, leurs ancres et liens vers les médias (activé par l'option séparée Parse People also ask)
- Réponse de l'IA (AI overview), son type et la liste des sources
Fonctionnalités
Le scraper du moteur de recherche Google possède de nombreuses fonctionnalités et paramètres :
- prise en charge de tous les opérateurs de recherche Google (site:, inurl:, etc.)
- spécification de la taille des résultats (10, 20, 30, 50 ou 100 résultats) et du nombre de pages (de 1 à 10) ; avec les paramètres maximaux, Google fournit de 300 à 500 résultats par requête, et grâce à la multiplication des requêtes, A-Parser contourne facilement cette limite
- possibilité de navigation automatique via les mots-clés associés
- spécification de la langue et du pays des résultats, possibilité de choisir le domaine local de Google, ainsi que la langue de l'interface
- possibilité de spécifier la géolocalisation, ce qui permet d'obtenir des résultats locaux précis pour n'importe quel endroit sur le globe
- choix entre l'affichage ordinateur ou mobile
- possibilité de choisir le type de résultats : en plus des résultats organiques principaux, le scraper Google peut collecter les résultats actualités, livres ou vidéos
- si nécessaire, possibilité de connecter la reconnaissance automatique ReCaptcha2 via des services de résolution ou via XEvil/CapMonster
- prise en charge de la spécification de la période des résultats (toute période ou intervalle spécifique de 24 heures à un an)
- possibilité de désactiver le filtre de Google masquant les résultats similaires (filter=)
- possibilité de spécifier s'il faut scraper les résultats si Google signale qu'aucun résultat n'a été trouvé pour la requête spécifiée et propose des résultats pour une requête similaire
- possibilité de définir le nombre de People also ask que le scraper doit collecter en cliquant en profondeur sur chaque question
- possibilité de collecter les tags
Les scrapers suivants fonctionnent sur la base du scraper Google :
 SE::Google::Position - détermination des positions de n'importe quels sites dans les résultats de recherche selon une liste de requêtes
SE::Google::Position - détermination des positions de n'importe quels sites dans les résultats de recherche selon une liste de requêtes SE::Google::Compromised - vérifie la propreté des domaines du point de vue de Google, capable d'identifier les sites piratés et de phishing
SE::Google::Compromised - vérifie la propreté des domaines du point de vue de Google, capable d'identifier les sites piratés et de phishing SE::Google::TrustCheck - vérifie le Trust (confiance) de Google envers un site
SE::Google::TrustCheck - vérifie le Trust (confiance) de Google envers un site
Cas d'utilisation
- Collecte de bases de liens - pour XRumer, AllSubmitter, GSA Ranker, etc.
- Dump complet de la SERP incluant liens, ancres, snippets, blocs publicitaires et autres informations permettant une analyse approfondie pour les spécialistes SEO et les marketeurs
- Évaluation de la concurrence pour les mots-clés
- Évaluation de la concurrence dans les résultats PPC (publicitaires)
- Recherche de backlinks et de mentions de sites
- Vérification de l'indexation des sites
- Recherche de sites vulnérables
- Tout autre cas impliquant l'obtention de résultats de recherche pour un nombre illimité de requêtes
Requêtes
Comme requêtes, il est nécessaire d'indiquer des phrases de recherche, exactement comme si vous les saisissiez directement dans le formulaire de recherche Google, par exemple :
achat voiture
fenêtres à paris
site:https://lenta.ru
inurl:guestbook
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour multiplier les requêtes. Par exemple, si nous voulons obtenir une très grande base de forums, indiquons quelques requêtes de base dans différentes langues :
forum
forum
foro
论坛
Dans le format de requête, indiquons une itération de caractères de a à zzzz ; cette méthode permet de faire pivoter au maximum les résultats de recherche et d'obtenir de nombreux nouveaux résultats uniques :
$query {az:a:zzzz}
Cette macro créera 475254 requêtes supplémentaires pour chaque requête de recherche initiale, ce qui donnera au total 4 x 475254 = 1901016 requêtes de recherche, un chiffre impressionnant, mais ce n'est pas du tout un problème pour A-Parser. À une vitesse de 2000 requêtes par minute, une telle tâche sera traitée en seulement 16 heures.
Utilisation des opérateurs
Vous pouvez utiliser des opérateurs de recherche dans le format de requête, ainsi ils seront automatiquement ajoutés à chaque requête de votre liste :
inurl:$query
Exemples de formats de sortie
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarits intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme libre, ainsi que structurée, par exemple CSV ou JSON.
Export d'une liste de liens
Format du résultat :
$serp.format('$link\n')
Exemple de résultat :
https://www.weforum.org/open-forum/
https://www.weforum.org/about/world-economic-forum/
https://www.merriam-webster.com/dictionary/forum
https://en.wikipedia.org/wiki/Forum
https://dictionary.cambridge.org/dictionary/english/forum
https://www.collinsdictionary.com/dictionary/english/forum
https://www.linkedin.com/company/world-economic-forum
https://docs.moodle.org/en/Forum_activity
https://wordpress.org/support/forums/
https://www.facebook.com/worldeconomicforum/
...
Liens + ancres + snippets avec affichage de la position
Format du résultat :
[% FOREACH item IN serp; loop.count _ ' - ' _ item.link _ ' - ' _ item.anchor _ ' - ' _ item.snippet _ "\n"; END %]
Exemple de résultat :
1 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC - Forum — Wikipédia - <em>Fórum</em> (lat. forum — arch. entrée d'un tombeau ; aire dans un pressoir pour le raisin à traiter ; place du marché, marché de la ville ; ...
2 - https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC_(%D0%BC%D0%B5%D1%80%D0%BE%D0%BF%D1%80%D0%B8%D1%8F%D1%82%D0%B8%D0%B5) - Forum (événement) — Wikipédia - <em>Forum</em> — événement organisé pour désigner ou résoudre des<wbr>problèmes suffisamment globaux. Ce concept se retrouve dans ...
3 - https://support.google.com/googleplay/community?hl=ru - Bienvenue sur le forum d'aide de la communauté ... - Bienvenue sur le <em>forum</em> d'aide de la communauté Google Play. Messages sélectionnés. Voir tous les messages intéressants · Besoin d'aide avec un jeu ?
4 - https://support.google.com/mail/community?hl=en - Gmail Community - Google Support - Welcome to the Gmail Help Community · Featured posts · Categories.
5 - https://www.weforum.org/ - The World Economic Forum - The World Economic Forum is an independent international organization committed to improving the state of the world by engaging business, political, academic ...
6 - https://www.kunena.org/ - Home - Kunena - To Speak! Next Generation Forum ... - Kunena! - To Speak! Next Generation Forum Component for Joomla.
7 - https://forum.adguard.com/index.php - AdGuard Forum - <em>Forum</em> des bêta-testeurs. Écrivez ici vos rapports de bugs des versions bêta. Threads: 355. Messages: 11.6K. Sub-forums: Commentaires sur les versions bêta ...
8 - https://www.sofiaforum.bg/ - Sofia Security Forum : Plateforme de discussion ... - Sofia <em>Forum</em> Security / Sofia Security Forum.
9 - https://forum.keenetic.net/ - Forums - Keenetic Community - Keenetic fan club. A place to meet software developers, get the latest updates, and share experience.
10 - https://forum.euroaion.com/ - Perfect quality European private server of Aion - EuroAion.com - Perfect quality European private server of Aion!
...
Sortie des liens, ancres et snippets dans un tableau CSV
L'utilitaire intégré $tools.CSVLine permet de créer des documents tabulaires corrects, prêts à être importés dans Excel ou Google Sheets.
Format général du résultat :
[% FOREACH i IN p1.serp; tools.CSVline(i.link, i.anchor, i.snippet); END %]
Nom du fichier :
$datefile.format().csv
Texte initial :
Lien,Ancre,Snippet
Exemple de résultat :
Lien,Ancre,Snippet
https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%83%D0%BC,"Forum — Wikipédia",
https://en.wikipedia.org/wiki/Forum,"Forum - Wikipedia","<em>Forum</em> (plural forums or fora) may refer to: Contents. 1 Common uses; 2 Places. 2.1 Natural features; 2.2 Populated places. 3 Arts and entertainment; 4 Media."
https://www.weforum.org/,"The World Economic Forum","The World Economic <em>Forum</em> is an independent international organization committed to improving the state of the world by engaging business, political, academic ..."
https://support.google.com/webmasters/community?hl=ru,"Bienvenue sur le forum d'aide de la communauté ...","Bienvenue sur le <em>forum</em> de la communauté Google Search Central. Messages sélectionnés. Voir tous les messages intéressants · Réponses à ..."
https://support.google.com/chrome/community?hl=ru,"Bienvenue sur le forum d'aide de la communauté ...","Bienvenue sur le <em>forum</em> de la communauté Google Chrome. Sélectionnés ..."
...
Dans le Format général des résultats, le moteur de gabarits Template Toolkit est utilisé pour afficher le tableau $serp dans une boucle FOREACH.
Dans le nom du fichier de résultats, il suffit de changer l'extension du fichier en csv.
Pour que l'option "Texte initial" soit disponible dans l'Éditeur de tâches, vous devez activer "Plus d'options". Dans "Texte initial", nous inscrivons les noms des colonnes séparés par des virgules et nous laissons la deuxième ligne vide.
Sortie des blocs publicitaires
Format du résultat :
$ads.format('$link - $anchor - $snippet\n')
Exemple de résultat :
https://www.rentalcars.com/ - Rent a Car Worldwide - Best Prices Online Guaranteed - Secure Your <em>Car Hire</em> Today. The Best Price Guaranteed. Book at Over 53,000 Locations. Search, Compare and Save Using the World's Biggest Online <em>Car Rental</em> Service.
https://www.kayak.com/United-States-Car-Rentals.253.crc.html - United States from $9/day - Search for Rental Cars on Kayak - Find and Compare Great <em>Car</em> Deals in USA. Book with Confidence on KAYAK®!
https://www.discovercars.com/ - -70% Worldwide Car Rental - Rent Your Car in 5 Minutes - <em>Car rental</em> prices are rising, but if you act fast, you can get a good deal. Don’t stress! We...
https://www.economybookings.com/ - Rent a Car for Summer Holidays - Car Rentals for the Best Price - Theft protection and Third Party liability part of a great deal. Free Mileage included.
...
Sauvegarde des mots-clés associés
Format du résultat :
$related.format('$key\n')
Exemple de résultat :
test <b>speed</b>
<b>net speed</b> test
<b>google speed</b> test
<b>fast speed</b> test
<b>ping</b> test
<b>xfinity speed</b> test
<b>speed</b> test <b>mobile</b>
test <b>my</b>
...
Pour supprimer automatiquement les balises HTML dans le résultat, vous devez utiliser le Constructeur de résultats, sélectionner le tableau $related et appliquer Remove HTML tags.
Concurrence des mots-clés
Format du résultat :
$query - $totalcount\n
Exemple de résultat :
speed test mobile - 1080000000
test score - 4020000000
net speed test - 1210000000
fast speed test - 2150000000
speed test - 2500000000
test match - 4160000000
ping test - 425000000
google speed test - 1870000000
Détection des mots-clés avec fautes de frappe
Format du résultat :
$query - $misspell\n
Exemple de résultat :
spead test - 1
test match - 0
speed test - 0
temst match - 1
Vérification de l'indexation des liens
Format de la requête :
site:$query
Format du résultat :
$query.orig - $totalcount\n
Exemple de résultat :
https://a-parser.com/pages/buy - 2
https://a-parser.com/wiki/parsers - 4
https://a-parser.com/resources - 883
https://trjkjfkdf.bg.ky - none
https://a-parser.com/forum - 371
Pour vérifier l'indexation des liens, nous insérons dans le Format de requête l'opérateur correspondant : site:.
Le format du résultat est affiché sous la forme "url source - nombre de pages dans l'index".
En résultat, nous obtenons l'adresse des pages et leur nombre dans l'index du moteur de recherche.
Si la page est absente, le résultat sera : none.
Sauvegarde au format SQL
Format du résultat :
[% FOREACH serp; "INSERT INTO serp VALUES('" _ query _ "', '"; link _ "', '"; anchor _ "')\n"; END %]
Exemple de résultat :
INSERT INTO serp VALUES('test', 'https://www.speedtest.net/', 'Speedtest by Ookla - The Global Broadband Speed Test')
INSERT INTO serp VALUES('test', 'https://fast.com/', 'Fast.com: Internet Speed Test')
INSERT INTO serp VALUES('test', 'https://www.business-standard.com/article/sports/ind-vs-aus-live-score-4th-day-5-india-vs-australia-live-cricket-score-online-brisbane-weather-121011900103_1.html', 'IND vs AUS 4th Test highlights: India creates history, wins ...')
INSERT INTO serp VALUES('test', 'https://www.test.com/', 'Find online tests, practice test, and test creation software | Test ...')
INSERT INTO serp VALUES('test', 'https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4', 'Recent Match Report - Australia vs India 4th Test 2020 ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/world-test-championship/standings', 'World Test Championship (2019-2021) Points Table - Live ...')
INSERT INTO serp VALUES('test', 'https://www.icc-cricket.com/rankings/mens/team-rankings/test', 'ICC Test Match Team Rankings International Cricket Council')
INSERT INTO serp VALUES('test', 'https://projectstream.google.com/speedtest', 'Speedtest - Google')
INSERT INTO serp VALUES('test', 'https://www.google.com/search?hl=en&q=Software+Testing&stick=H4sIAAAAAAAAAONgecQ4g5Fb4OWPe8JSfYyT1py8xtjOyMUVnJFf7ppXkllSKaTCxQZlSXHxSHHo5-obmJul5GkwSHFxwXlKwUbuuy5NO8fmKMgABGJm_g5SmlpCXOyexT75yYk5ggpvuB68mfLeXkuYiyMksSI_Lz-3UtCBgcHhx__39kqcnEBND7aoddhrMTTtW3GIjYWDUYCBZxGrQHB-Wkl5YlGqQkhqcUlmXjoAS5B1P7EAAAA&sa=X&ved=2ahUKEwiW-rnmlajuAhWpAGMBHR-JAv4Q6RMwHXoECDQQBQ', '')
...
Dump des résultats en JSON
Format de sortie general:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.links = [];
FOREACH item IN p1.serp;
obj.links.push(item.link);
END;
obj.json %]
Texte initial:
[
Texte final:
]
Exemple de résultat :
[{"totalcount":"6450000000","links":["https://www.speedtest.net/","https://fast.com/","https://projectstream.google.com/speedtest","https://www.test.com/","https://www.speakeasy.net/speedtest/","https://www.att.com/support/speedtest/","https://speedtest.xfinity.com/","https://developers.google.com/speed/pagespeed/insights/","https://www.espncricinfo.com/series/india-in-australia-2020-21-1223867/australia-vs-india-4th-test-1223872/match-report-4","https://nasional.tempo.co/read/1424570/listyo-sigit-temui-ahy-menjelang-fit-and-profer-test-calon-kapolri","https://www.google.com/search?hl=en&q=Test+Assessment&stick=H4sIAAAAAAAAAONgecRYyC3w8sc9YamMSWtOXmNM4uIKzsgvd80rySypFNLiYoOyFLj4pbj10_UNjQyzKsvyzDQYpHi5kAWUNIxkdl2ado5NTJABCMTKAhyUODmBLIVA-wX2WgxN-1YcYmPhYBRg4FnEyh-SWlyi4FhcnFpcnJuaVwIAwEAP9ogAAAA&sa=X&ved=2ahUKEwj17MzXmajuAhW8CWMBHRlzBP4Q6RMwDHoECBEQBQ"]}]
Pour que les options "Texte initial" et "Texte final" soient disponibles dans l'Éditeur de tâches, vous devez activer "Plus d'options".
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte de données ; dans cette section, nous avons listé les cas les plus populaires pour le scraper Google.
Déduplication des liens
Ajouter la déduplication et sélectionner dans la liste déroulante $serp.$i.link - Link.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE1v2zAM/SsFkcMGBEFy2MW3NFiKDVnTNekpyEGNaUOLLGmSnDUw/N9H+ktO
N/Rmko+PfCTlCoLwZ//k0GPwkBwqsM03JLD7miQPxuQK7zZSn/3di5a/S4QpWOE8
OoYfRigKpJiJUgWYVhCuFonEXNA5mXJQpmRbZ96uDoOT6Ml3Eapk2GI+n0P9QZrI
8WRKHWLO4gO44n4tOk4bZcxHKWUvhuRyy8kBSJMlByfDcdoh9i3cU8c6h977oMyr
UJAEV2J9PPYsfm1cIXh4E7uYdZMcgjtxwb2hYCZVrOzXZD2KgqtMUhGQo7OsIfr0
eRbemEGkqQzSaKHaCjz7WLVbTALaEJY+ebprZwpyBWwI2HntuzvApLGjyp9tDiSZ
UB6n4KnVtaBG0vcRGdCJYNzWcj/kr8DopVIbvKCKsIb/vpQqpUNZZpT0rUv8P2T7
D0c9yBuXokX/cdTDwNJY99sfMSs1G5OT8vS1WWYhA9l+1VxPAnNynhHtMLNHnllh
HA5lOuauOr0Ni5qvKq5saaPrRsbNWm6dJ6MzmW+7S+2Rpd7TA9zqlSmsQtalS6Vo
LR6f43ksfbcGNmKD75NXTQmW3r9DCMYo/33XtmqdpPP7wg0WNMlx1Y7yJJR6ed6M
IxBPqjknz7QnutPc0AWRivo4/BGG/0g1/i8kVU1r+eWfWhBrYAj5aBieZs6P+S/t
6pW4
Voir aussi : Déduplication des résultats
Déduplication des liens par domaine
Ajouter la déduplication et sélectionner dans la liste déroulante $serp.$i.link - Link. Choisir le type de déduplication : Domaine.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE2P2jAQ/SvI4tBKaAWHXnJj6bJqRZftwp4QB0MmyMXxuLZDF0X89844IQ7b
am+ZmffefDq1CNIf/bMDD8GLbFMLG79FJlYPWfaIeNAwWChz9INXo35XMNidB1+x
lMqIkbDSeXBM3PTwFMihkJUOYlSLcLZAcngC51TOQZWTbR2+nR0Ep8CT7yR1xbDJ
eDwWlw9o8gB7rExInMkHcM2VW3BM6zHGPUoV26IgNc4lZxtBPVlyMFlsRy1i3cDz
a++N91HjTmqRBVfBZbu9qvg5ulLyGId2ctfOtAuu5AnWSMFC6ZTZz8l6kiVnGeYy
AEfviij06fNdeGMFmecqKDRSNxl49ilrsyLiGyQsffJ05w5LcgWIAuw8X6vbiGG0
U5c/G47ICqk9jISnUueSCsnfR1QAJwO6peV6yF8LNFOtF3ACnWBR/75SOqdDmRZE
+tYS/w9Z/qNx6drrp6JF/3FUQ6cSrfvlj8TKcYEHXtkuLrNUgWw/i9eTiTE5jwC2
m9kTz6xEB12aVrnNTq/EguGrSiub2uS6aeNmLbfOPZpCHZbtpV6RlVnTU1yaGZZW
A/dlKq1pLR5e0nlMfbsGNlKB78mzmIJbv75DERC1/75qSrVO0fl94QJLmmQ/ayu5
l1q/viz6EZFOKp6TZ9k93ekB6YKoi8u2+yN0f5S6/1/I6gut5Zd/bkDcA0PIR8Pw
NHN+zH8BRVyZDA==
Voir aussi : Déduplication des résultats
Extraction de domaines
Ajouter un Results Builder (Constructeur de résultats) et sélectionner dans la liste déroulante la source : $p1.serp.$i.link - Link. Choisir le type : Extract Domain.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE1v2zAM/SuFkMMGBIFz2MW3NGuGDVnTNe0p6EGzaUOLLGqSnCUw8t9HKort
dkNv5scj+cgndyJIv/cPDjwEL/JdJ2z8FrnY3uX5F8Raw83dMThZhJvP2EhlxFRY
6Tw4BuxGeRQooZKtDmLaiXCyQGXwAM6pkoOqJNs6PJ4cBKfAk+8gdctp8yzLxPkd
mKyhwNaEATN/J10rs/cWHMNGiOz88jIVxJBm9Ct0jWSmEzufJdp9cCsP8IQUrFQk
dsWQdS8bbjkpZQCOzqpY6MPHWThyBVmWKig0Ul868JqGrs9G/Y6MDVIuffIiVg4b
cgWIBdh5uk63E5NoCyrRRuyPC0bkldQepsLTqCtJg5RvIyqAkwHdxvI85O8EmoXW
aziAHtJi/dtW6ZJuuqgI9DUB/5+y+afGuac3bkU3+eNohr5KtG433wdUiWusiXn5
k3hr1ahAtl/GQ+ciI+cewPY7u+edNeigb5Mqp+4kZAuGBTCcbGEH1ysar84ycnbC
Y+sK6rfLpjtBQrdxOLMXrJ6kOLi8if5JSOfkifwpPWBSoTgTpkBTqXqTRHrt3Jon
en0bs8TGauA9mVZrOrOHx0FuC5/OysZA+C14GVvwKq9PkGZA7b9tL9StUzTSJybc
0GXGXVPJQmr9/LgeR8Qg0ShPz2UL0n2NpEhiweTSz6D/iXTjX0LenenMv/zDJYk5
cAr5aBmebsjv+C86oZM/
Voir aussi : Constructeur de résultats
Suppression des balises des ancres et snippets
Ajouter un Results Builder (Constructeur de résultats) et sélectionner dans la liste déroulante la source : $p1.serp.$i.anchor - Anchor. Choisir le type : Remove HTML tags.
Ajouter à nouveau un Results Builder (Constructeur de résultats) et sélectionner dans la liste déroulante la source : $p1.serp.$i.snippet - Snippet. Choisir le type : Remove HTML tags.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJyVVD1v2zAQ/SsC4aEFBEMeumhzjLpp4cSp7UxGBlY6qawpkiUpN4bg/947mpaU
NAjQjby79+7rkR3z3B3cgwUH3rF83zETzixn2895/kXrWkKygUYfIbnd3a0Sz2uX
VFY3yVwVP7V1CVdlslXCGKJImeHWgSWy/YgDHSVUvJWepR3zJwOYAkmtFSU5RYl3
Y/XzyYK3AojpyGVLYbMsy9j5HRivodCt8gNm9k64FOrgDFiCjRDZ+ekpZdg91uiW
2jacpjAxs2kcSe/c8iPsNDorERq7YvB2zxtKOSm5B/JOq0D04ePUPxMDL0vhhVZc
XjLQmIasj0r8Dh0rjbF4pEEscdZo8hAIyHi6Vrdnk3BnSNEG7PcLhuUVlw5S5rDU
JcdCytce4cFyr+3aUD1o75hWcylXcAQ5hAX+m1bIEnc6rxD0NQLfDln/w3Hu2xun
wp38sVhDzxJuN+u7AVXqla6x8/IH9i1FIzze3SIsOmcZGg8App/ZPc2s0Rb6NJE5
ZkeRG1AkgGFlczOYXrTxYi0jY8ecbm2B+fZZumcodENbDS+BkX6i5mx4Mbe+keS2
lp/QGKM9SSdCSKZvMbrLe/ovyivmjJhCq0rU66j8azut2uFzX6uFbowEGr5qpUTt
ONgMGp67qBW6DFN8DV6EFLSf67vGMrR037aXeRorsKpPaSx8nDVSFlzKx81q7GGD
7oPmHdEW+JhqjTLHLqi5+MP0v1Y3/mfy7oza+eUeLkHUA4WgDYfhUBj0OfwFH/O5
UQ==
Vous pouvez ajouter le Constructeur de résultats autant de fois que nécessaire.
Voir aussi : Constructeur de résultats
Filtrage des liens par occurrence
Ajouter un filtre et sélectionner dans la liste déroulante : $serp.$i.link - Link. Choisir le type : Contient la chaîne. Ensuite, dans String (Chaîne), inscrivez le critère de filtrage.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx9VE1v2kAQ/StoxSGVEIJDL74RVKpWNKSBnBCHDR5bG9Y72901DbL83zuzNrZJ
qtw8H+/Nm491JYL0J//owEPwItlXwsZvkYjttyT5jphrGK2UDuCUyUcvl5EP8UuZ
kVbmJCbCSufBMXo/AFEghUyWOohJJcLFAnHiGZxTKQdVSrZ1+HZxQIzgyXeWuuS0
+Ww2E/UnMJnDEUsTesz8k3TW6S04hg0QswEkix1SkLpnycleUE+WHLHJw6TN2DXp
RzRBKjOQPD1iQSbaoNCQ7cF4UR8OV0a/QldInuvYzqftkLvgVp5hh40O6N00d3iQ
BfOPUxmAo9MsEt19mYY3ZpBpqrim1E0F3kNf9dmoP1GfQcqlT570ypHWRASIBOy8
XNXtxTja3HEZsb8bjEgyqT1MhCepK0lC0vcRRfORAd0mzoD8lUCz0HoNZ9B9WuS/
L5VO6WgWGYF+tMD/p2w+cNRde8NStPS/jjR0LNG63/zqUSmuMafO05e42EIFsv0y
XlIiZuQ8AdhuZg88swIddGVa5rY6PRsLhi+sX9nC9q6bNm7Wcuuka8pUvmmv9ppZ
mh29zY1ZYmE1cF+m1JrW4uGpP4+Fb9fARi/wPXgZS3Dr1zcpAqL2P7eNVOsUnd9X
FljQJIdVW8qj1Pr5aT2MiP6k4jl5pj3SneZIF0Rd1Ifu79D9YqrhPyKpalrLq39s
krgHTiEfDcPHlzSv/wHtZp3U
Voir aussi : Filtres de résultats
Paramètres possibles
Paramètres régionaux
Google domain - domaine Google utilisé, par défaut google.com
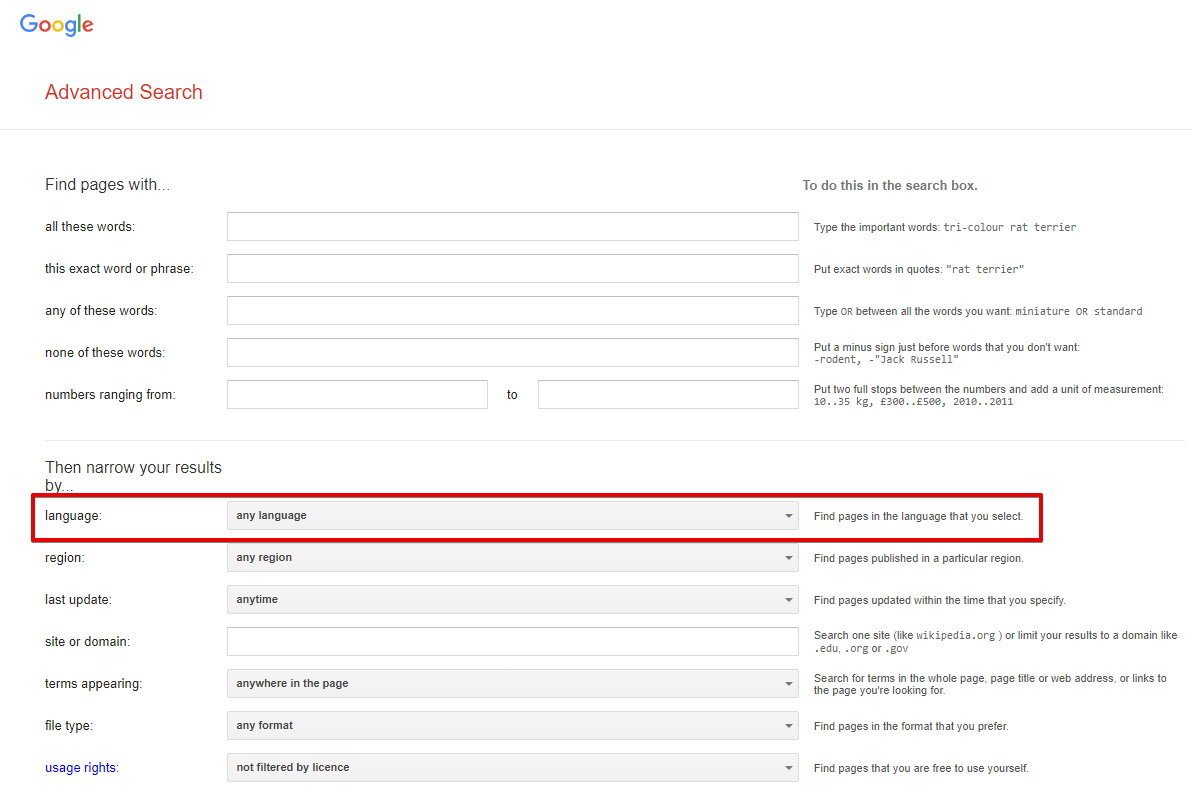
Results language - recherche de pages dans la langue sélectionnée ; dans le navigateur, cela correspond à l'option Recherche avancée -> Paramètres supplémentaires -> Rechercher dans (paramètre d'URL lr). Par défaut non défini, ce qui signifie une détection automatique basée sur l'IP.
Spoiler : Capture d'écran
Interface language - langue des produits Google ; dans le navigateur, cela correspond à Langues -> Langue de l'interface (paramètre d'URL hl). Par défaut, l'anglais est sélectionné.
Spoiler : Capture d'écran
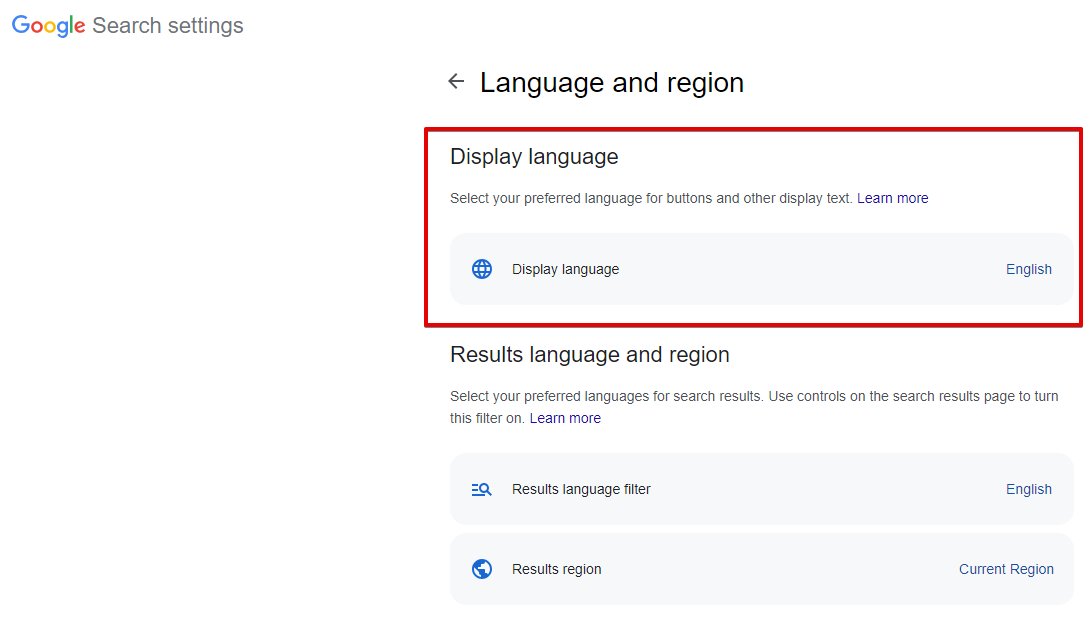
Search from country - choix de la région de recherche ; dans le navigateur, cela correspond à Langues -> Région de recherche (paramètre d'URL gl). Par défaut non défini, ce qui signifie une détection automatique basée sur l'IP.
Spoiler : Capture d'écran
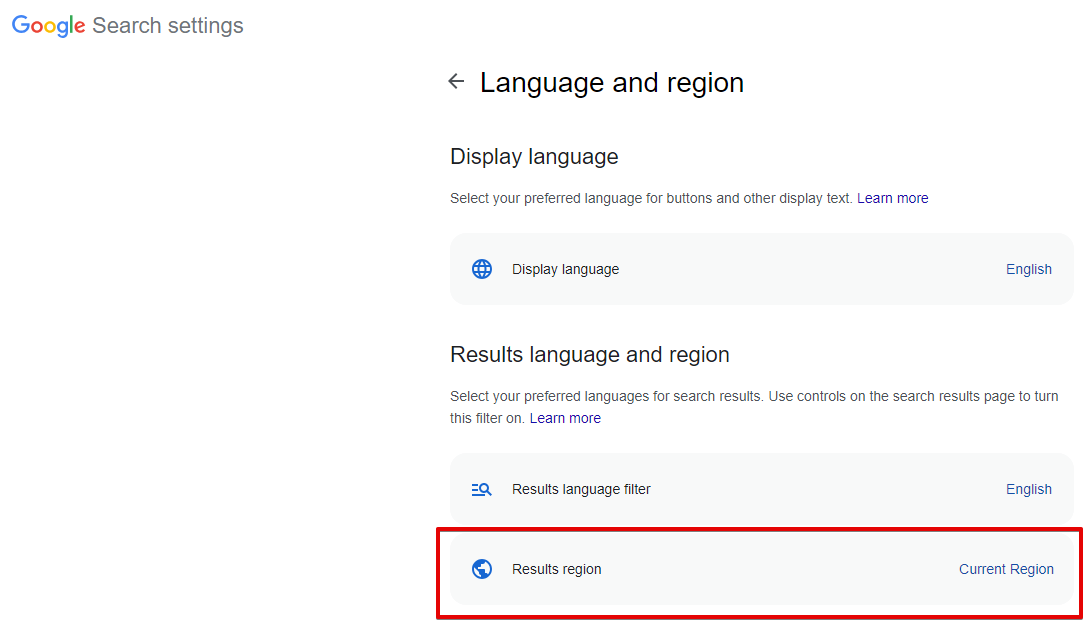
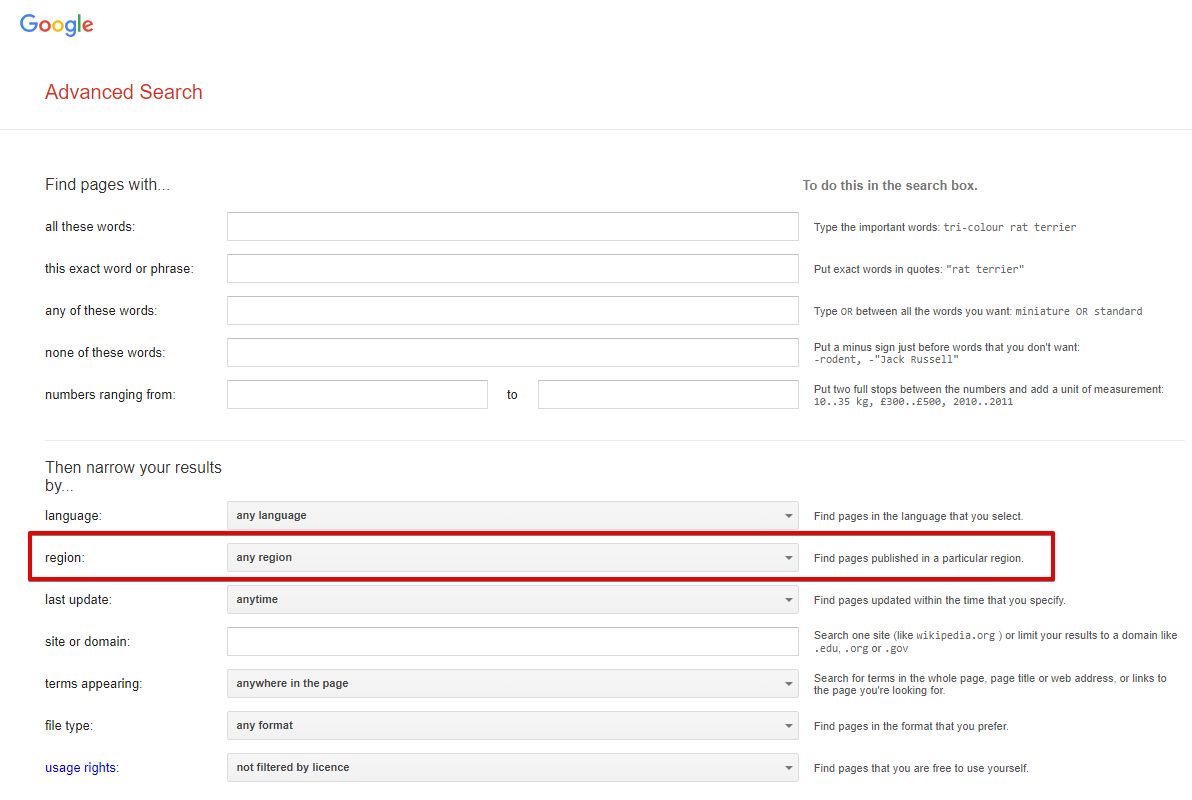
Narrow results by region - recherche de pages créées dans un pays spécifique ; dans le navigateur, cela correspond à Recherche avancée -> Paramètres supplémentaires -> Pays (paramètre d'URL cr). Par défaut non défini, ce qui signifie que cette option est désactivée.
Spoiler : Capture d'écran
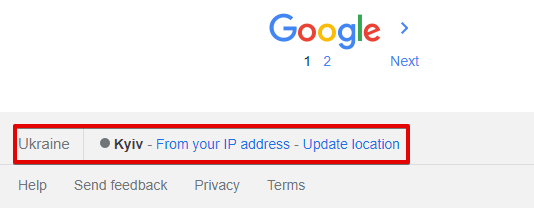
Location (city) - emplacement exact de la recherche ; dans le navigateur, il est déterminé automatiquement en fonction de la position de l'utilisateur. Par défaut non défini, ce qui signifie une détection automatique basée sur l'IP de la requête.
Spoiler : Capture d'écran
Tous les paramètres régionaux influencent plus ou moins les résultats.
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Device | Desktop | Choix de l'affichage ordinateur ou mobile : Desktop / Mobile |
| Pages count | 5 | Nombre de pages à scraper (de 1 à 100) |
| Serp type | Default (All) | Détermine s'il faut scraper depuis la page principale, par actualités ou par livres (Books, News, Videos) |
| Hide omitted results | ☑ | Détermine s'il faut masquer les résultats omis (paramètre filter=) |
| Serp time | Anytime | Période de la SERP (recherche temporelle, paramètre tbs=, valeurs possibles : Past 1 hour, Past 24 hours, Past week, Past month, Past year) |
| Parse not found | ☑ | Détermine s'il faut scraper les résultats si Google signale qu'aucun résultat n'a été trouvé pour la requête spécifiée et propose des résultats pour une autre requête |
| Disable autocorrect | ☐ | Permet de désactiver l'autocorrection de Google et de scraper les résultats précisément pour la requête indiquée |
| Exact match | ☐ | Correspond à l'option "Mot à mot" dans le moteur de recherche. Attention, cette option écrase la valeur du paramètre Serp time (similaire au fonctionnement de ces options dans le navigateur). |
| Safe search | Blur | Possibilité d'activer le "SafeSearch" |
| Google domain | www.google.com | Domaine Google pour le scraping, tous les domaines sont pris en charge (www.google.ac, www.google.com.af, www.google.co.ck etc.) |
| Narrow results by region | Any region | Possibilité de restreindre la recherche à un pays spécifique |
| Results language | Auto (Based on IP) | Choix de la langue des résultats (paramètre lr=) |
| Search from country | Auto (Based on IP) | Choix du pays depuis lequel la recherche est effectuée (recherche géo-dépendante, paramètre gl=) |
| Interface language | English | Possibilité de choisir la langue de l'interface Google, pour une identité maximale des résultats entre le scraper et le navigateur |
| Location (city) | Recherche par ville, région. On peut indiquer les villes sous la forme novosibirsk, russia ; la liste complète des emplacements se trouve dans Geotargets (copie - il faut utiliser la valeur de la colonne Canonical Name). Il est également nécessaire de définir le domaine Google correct | |
| Util::ReCaptcha2 preset | default | Détermine s'il faut utiliser  Util::ReCaptcha2 pour contourner les reCAPTCHA Util::ReCaptcha2 pour contourner les reCAPTCHA |
| Util::AntiGate preset | default | Détermine s'il faut utiliser  Util::AntiGate pour contourner les captchas graphiques Util::AntiGate pour contourner les captchas graphiques |
| ReCaptcha2 retries | 3 | Nombre de tentatives d'envoi de la réponse au reCAPTCHA le nombre de fois indiqué, sans changer de proxy |
| ReCaptcha2 pass proxy | ☐ | Permet de transmettre les proxies (utilisés dans la requête à Google) et les cookies (reçus dans la réponse de Google) au service de reconnaissance ReCaptcha |
| Use sessions | ☑ | Sauvegarde les bonnes sessions, ce qui permet de scraper encore plus vite en recevant moins d'erreurs. |
| Don't take session | ☐ | Possibilité de ne pas utiliser les bonnes sessions sauvegardées |
| Additional headers | Permet de spécifier n'importe quels en-têtes personnalisés | |
| PAA questions count | 0 | Nombre maximal de questions-réponses (People also ask) par requête que le scraper doit collecter |
| Empty totalcount is error | ☐ | En activant ce paramètre, la requête sera considérée comme échouée si la valeur pour $totalcount est absente, et des tentatives répétées seront effectuées en conséquence |
| Redirect browser max pages | 10 | Nombre de pages de navigateur utilisées pour contourner la protection sous forme de vérification du JavaScript activé |
| Single redirect browser for task | ☑ | Si plusieurs scrapers Google sont indiqués dans la tâche — utiliser un seul navigateur pour toutes les sous-tâches ; le nombre maximal de pages et les autres paramètres sont pris du premier scraper Google de la tâche |