SE::Yandex::WordStat::ByDate - 按月或按周抓取 Yandex WordStat 展示统计数据的爬虫工具
爬虫工具概览
Wordstat 是 Yandex 的一项服务,旨在评估用户对各种主题的兴趣,并为 SEO 优化和上下文广告选择关键词。此外,借助 Wordstat Yandex,您可以评估搜索查询的季节性和地理依赖性。
Yandex WordStat by date 爬虫工具支持自动扩展查询,您可以放心获得最大数量的搜索结果。此外,A-Parser 可以按指定的深度自动跳转到相关查询。
A-Parser 的功能允许保存数据抓取设置以供将来使用(预设),设置数据抓取计划等等。您可以使用自动查询扩展、从文件替换子查询、遍历数字字母组合和列表,以获取尽可能多的结果。
由于内置了强大的模板引擎 Template Toolkit,可以将结果保存为您需要的任何形式和结构,该引擎允许对结果应用额外的逻辑,并以各种格式输出数据,包括 JSON、SQL 和 CSV。
爬虫工具应用案例
🔗 Wordstat bydate 自动化
用于在数据库中存储最新信息,并在每次运行时生成包含最新数据的 csv 文件
账号
运行爬虫工具  SE::Yandex::WordStat::ByDate 需要 Yandex 账号。可以使用爬虫工具
SE::Yandex::WordStat::ByDate 需要 Yandex 账号。可以使用爬虫工具  SE::Yandex::Register 注册账号,或者直接将现有账号以支持的格式添加到
SE::Yandex::Register 注册账号,或者直接将现有账号以支持的格式添加到 files/SE-Yandex/accounts.txt 文件中。
或者可以启用“实时”注册账号。
采集的数据
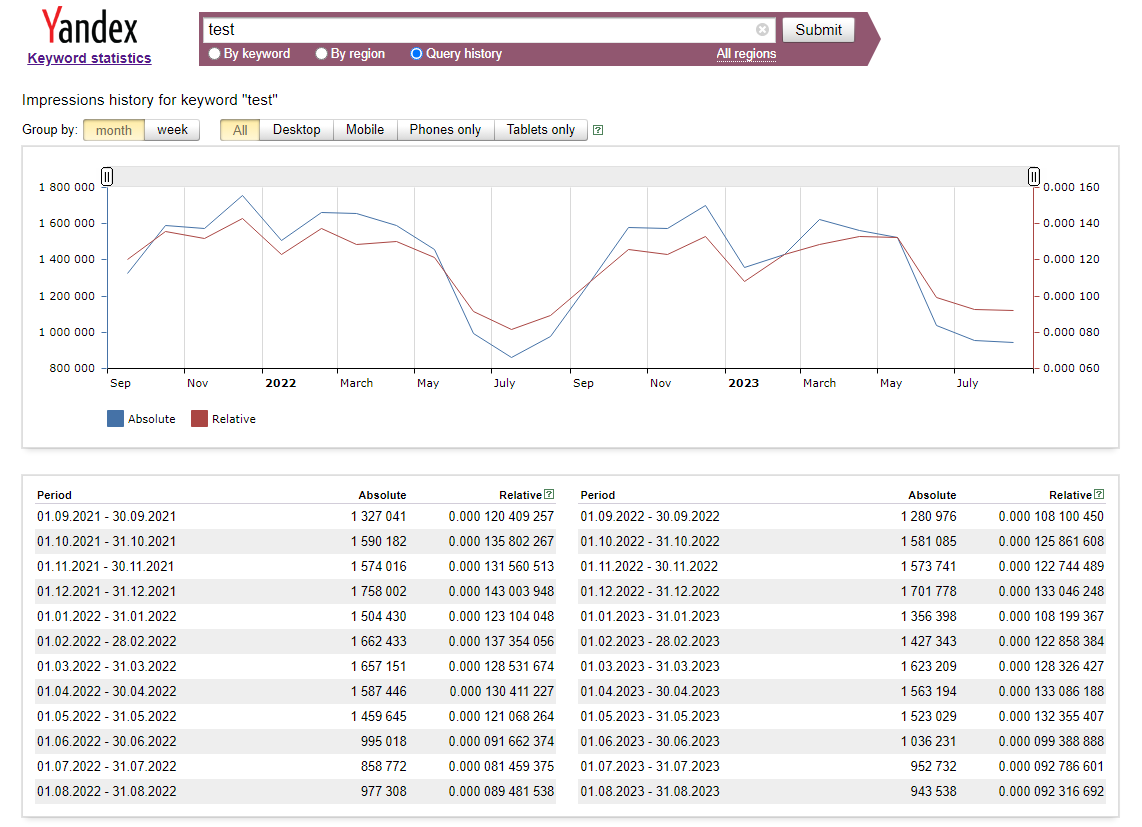
- 按月或按周的关键词统计数据
- 日期
- 绝对值
- 相对值
功能
- 支持选择搜索区域(带子组)
- 可以同时选择多个区域进行评估
- 支持自动绕过 Smart captcha,并能够使用 AntiCaptcha 服务或任何其他支持其 API 的服务绕过图形验证码
- 选择设备类型
- 可以选择登录验证方法
- 可以“实时”注册账号
- 支持使用扩展账号格式并能够回答安全问题(如果
info中有答案)。此外,还使用保存的代理进行登录验证(如果info中有代理)。
使用场景
- 评估关键词的流量大小
- 识别季节性关键词
查询
在查询中需要指定关键词,就像直接在 Wordstat 搜索框中输入一样,例如:
test
结果输出选项
得益于内置的模板引擎 Template Toolkit,A-Parser 支持灵活的结果格式化,这使其能够以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
默认输出
结果格式:
Views:\n$views.format('$date $count $relcount\n')
结果中显示了按月和按周的关键词统计数据:
Monthly:
2011-09-30 3010832 0.0008903808
2011-10-31 681432 0.0001825883
2011-11-30 628532 0.0001575008
2011-12-31 629072 0.0001495699
2012-01-31 561206 0.0001300651
2012-02-29 572039 0.0001290000
2012-03-31 614897 0.0001225754
2012-04-30 520433 0.0001185340
2012-05-31 521967 0.0001235327
2012-06-30 502568 0.0001299958
...
Weekly:
2012-09-16 118715 0.0001222877
2012-09-23 120799 0.0001211773
2012-09-30 137809 0.0001365837
2012-10-07 133929 0.0001313643
2012-10-14 140373 0.0001293922
2012-10-21 136014 0.0001242209
2012-10-28 148350 0.0001293328
2012-11-04 139556 0.0001232566
2012-11-11 154830 0.0001314057
2012-11-18 136458 0.0001147489
2012-11-25 149463 0.0001261401
2012-12-02 144724 0.0001197564
2012-12-09 149142 0.0001212195
2012-12-16 162864 0.0001298181
输出到 CSV 表格
结果格式:
[% FOREACH i IN views;
tools.CSVline(query, i.count, i.date);
END %]
结果示例:
"测试",9661734,2012-03-31
"测试",8567243,2012-04-30
"测试",9028986,2012-05-31
"测试",6082099,2012-06-30
"测试",5531950,2012-07-31
"测试",5214663,2012-08-31
"测试",6603865,2012-09-30
"测试",9127457,2012-10-31
"测试",9238652,2012-11-30
以 SQL 格式保存
结果格式:
[% FOREACH i IN views;
"INSERT INTO views VALUES('" _ query _ "', '"; i.count _ "', '"; i.relcount _ "', '"; i.date _ "')\n";
END %]
结果示例:
INSERT INTO serp VALUES('测试', '9661734', '0.0019259985', '2012-03-31')
INSERT INTO serp VALUES('测试', '8567243', '0.0019512785', '2012-04-30')
INSERT INTO serp VALUES('测试', '9028986', '0.0021368683', '2012-05-31')
INSERT INTO serp VALUES('测试', '6082099', '0.0015732140', '2012-06-30')
INSERT INTO serp VALUES('测试', '5531950', '0.0013160071', '2012-07-31')
INSERT INTO serp VALUES('测试', '5214663', '0.0013327945', '2012-08-31')
INSERT INTO serp VALUES('测试', '6603865', '0.0015936909', '2012-09-30')
INSERT INTO serp VALUES('测试', '9127457', '0.0018740506', '2012-10-31')
INSERT INTO serp VALUES('测试', '9238652', '0.0018308715', '2012-11-30')
将结果转储为 JSON
通用结果格式:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.views = [];
FOREACH item IN p1.views;
obj.views.push({
date = item.date
relcount = item.relcount
count = item.count
});
END;
obj.json %]
起始文本:
[
结束文本:
]
结果示例:
[{
"views": [
{
"count": "9661734",
"date": "2012-03-31",
"relcount": "0.0019259985"
},
{
"count": "8567243",
"date": "2012-04-30",
"relcount": "0.0019512785"
},
{
"count": "9028986",
"date": "2012-05-31",
"relcount": "0.0021368683"
}
]
}]
另请参阅:结果过滤器
可选设置
| 参数 | 默认值 | 描述 |
|---|---|---|
| Period | Monthly | 选择周期(Monthly/Weekly/Daily,Daily 仅在启用 Use Wordstat 2 选项时有效) |
| Start date | | 指定开始搜索的日期。仅在启用 Use Wordstat 2 选项时有效。必须遵守日期指定规则 |
| End date | | 指定结束搜索的日期。仅在启用 Use Wordstat 2 选项时有效。必须遵守日期指定规则 |
| Region | All | 搜索区域 |
| AntiGate preset | default | 需要预先配置  Util::AntiGate 爬虫工具 - 指定您的访问密钥和其他参数,然后在此处选择创建的预设 Util::AntiGate 爬虫工具 - 指定您的访问密钥和其他参数,然后在此处选择创建的预设 |
| AntiGate preset for Login | default | 用于登录的 AntiGate 预设。需要预先配置带参数的 Util::AntiGate 爬虫工具,然后在此处选择创建的预设 |
| Type | All | 选择设备类型 |
| Accounts | Only from "accounts.txt" | 选择账号处理方法:Always auto register - 始终“实时”自动注册账号,需要在 SE::Yandex::Register preset 参数中选择配置好的预设。Auto register if no more in "accounts.txt" - 首先使用 accounts.txt 中的现有账号,如果用完,则使用“实时”自动注册,为此需要在 SE::Yandex::Register preset 参数中选择配置好的预设。Only from "accounts.txt" - 仅使用 accounts.txt 中的现有账号,如果用完,则等待指定时间(Wait new accounts in "accounts.txt" 参数)直到出现新账号 |
| Wait new accounts in "accounts.txt" | 0 | 等待 accounts.txt 中出现新账号的时间 |
| Remove bad accounts | Always, except wrong login/password | 自动删除“坏”账号:Always - 始终删除。Always, except wrong login/password - 始终删除,除非 Yandex 提示登录名/密码错误。事实是,当 IP 被封禁时,Yandex 可能会对完全正常的账号给出此类提示,因此可以选择保留此类账号以供重复使用。Never - 从不删除。无论选择哪种选项,在代理/浏览器错误时都不会删除账号 |
| SE::Yandex::Register preset | default | 为 SE::Yandex::Register 选择设置预设 |
| Authorization method | HTTP | 登录验证方法:HTTP - 快速,对资源要求低。Chrome - 慢速,对资源要求高,理论上可以延长账号寿命 |
| Chrome headless | ☑ | 如果启用此选项,浏览器将不会显示 |
| Use sessions | ☑ | 使用会话 |
| Do not reset session if authorization passed | ☑ | 如果爬虫工具已通过验证,则在发生错误时不重置会话 |
| Use Wordstat 2 | ☐ | 使用 Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | 允许立即导出查询的所有 2000 个结果,而无需遍历分页 |