SE::Google::Suggest - Google 搜索建议爬虫工具
爬虫工具概览
Google 搜索建议关键词爬虫工具。借助 SE::Google::Suggest 爬虫工具,您可以根据查询请求自动从 Google 搜索系统的建议中收集关键词库。使用 SE::Google::Suggest 爬虫工具,可以根据选定的国家、语言或域名,轻松快速地抓取 Google 搜索建议。
Google 搜索建议爬虫工具解决了 SEO 的核心任务之一,即快速自动地获取扩展语义库。Google 搜索建议允许覆盖最大数量的短语,结合 Google 关键词爬虫工具  SE::Google::KeywordPlanner,您将获得最完整的语义,从而帮助吸引更多的有机流量。
SE::Google::KeywordPlanner,您将获得最完整的语义,从而帮助吸引更多的有机流量。
得益于 A-Parser 的多线程工作机制,查询处理速度可达每分钟 6000 次,平均每分钟可获取多达 45000-46000 条结果。
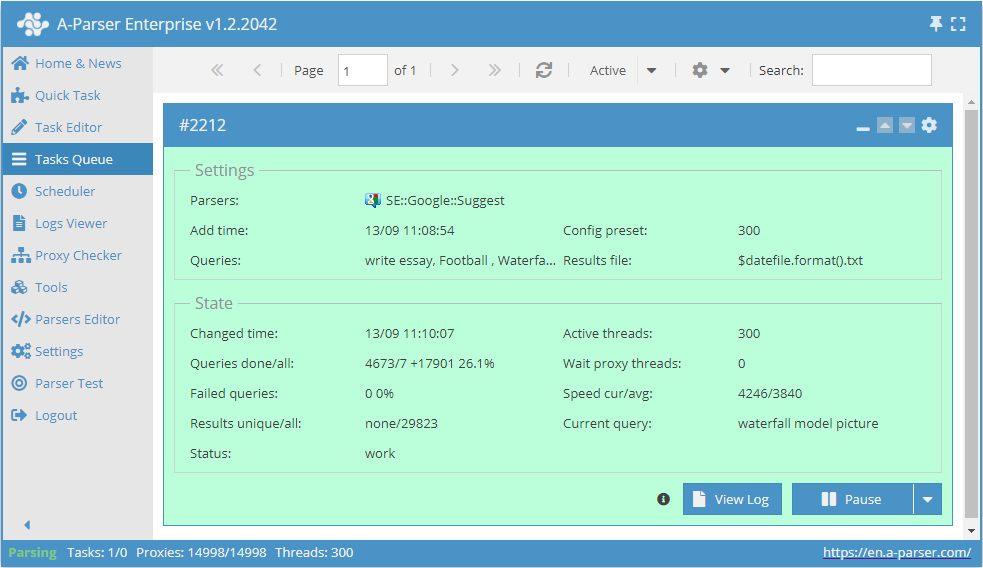
您可以使用自动查询扩展、从文件中插入子查询、穷举数字字母组合和列表,以获取尽可能多的结果。利用 结果过滤,您可以立即清洗结果,删除所有不需要的垃圾信息(使用否定词)。
A-Parser 的功能允许保存 SE::Google::Suggest 爬虫工具的数据抓取设置以供日后使用(预设),设置数据抓取计划等等。
得益于内置强大的模板引擎 Template Toolkit,结果保存可以采用您需要的任何形式和结构,该引擎允许对结果应用额外的逻辑,并以各种格式输出数据,包括 JSON、SQL 和 CSV。
爬虫工具应用案例
🔗 JS::Google::FromSnippets
在 JS 爬虫工具中使用内置爬虫工具的工作示例
采集的数据
- 每个查询的结果数量
- 查询建议
- 建议类型(0 - 人工,1 - 机器生成)
功能
- 支持选择搜索国家、域名、语言结果
- 可以选择来源,用于收集建议(Client 选项)
- 可以从抓取结果中删除 HTML 标签(Remove HTML tags 选项)
使用场景
- 收集关键词库
查询
在查询中需要指定搜索短语,例如:
write essay
Football
Waterfall
Speak in english
Cats and dogs
forex
cheap essay
查询替换
您可以使用 内置宏 自动从文件中插入子查询,例如我们想为每个查询添加一些其他单词列表,指定几个主要查询:
essay
article
thesis
在查询格式中指定从文件 Keywords.txt 插入额外单词的宏,此方法可以成倍增加查询的多样性:
{subs:Keywords} $query
该宏将为每个原始搜索查询创建与文件中行数相同的额外查询,宏运行后的结果为 [原始查询数量(域名)] x [Keywords 文件中的查询数量] = [总查询数量]。
例如,如果 Keywords.txt 文件包含:
buy
cheap
最终,替换宏将把 3 个主要查询变为 6 个:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
结果输出示例
得益于内置的模板引擎 Template Toolkit,A-Parser 支持灵活的结果格式化,使其能够以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
导出建议列表
结果格式:
$results.format('$suggest\n')
结果示例:
buy essays online
buy essay cheap
buy essay uk
buy essays online no plagiarism
buy essay papers
buy essay online reviews
buy essays reddit
buy essay friend
输出查询、查询建议 + 建议类型
结果格式:
$query:\n$results.format('$suggest - $type\n')
结果示例:
cheap essay:
cheap essay writing service - 1
cheap essay writing service uk - 1
cheap essay writing service canada - 1
cheap essay writing 24 - 1
cheap essays online - 1
cheap essay writing service reddit - 1
cheap essay writing service australia - 1
cheap essay writing service review - 1
buy essay:
buy essay online - 1
buy essay cheap - 1
buy essay uk - 1
buy essay papers - 1
buy essay online reviews - 1
buy essays reddit - 1
buy essay friend - 1
buy essay online uk - 1
输出到 CSV 表格
内置工具 $tools.CSVLine 允许创建正确的表格文档,可直接导入 Excel 或 Google 表格。
通用结果格式:
[% FOREACH i IN p1.results;
tools.CSVline(i.suggest);
END %]
文件名:
$datefile.format().csv
起始文本:
建议
在 通用结果格式 中应用了 Template Toolkit 模板引擎,用于在 FOREACH 循环中输出 $results 数组的元素。
在结果文件名中,只需将文件扩展名更改为 csv。
要使“Prepend text”选项在任务编辑器中可用,需要激活“More options”。 在“Prepend text”中按逗号分隔记录列名,并将第二行留空。
关键词竞争度
以 SQL 格式保存
结果格式:
[% FOREACH results; "INSERT INTO serp VALUES('" _ query _ "', '"; suggest _ "', '"; type _ "')\n"; END %]
结果示例:
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service uk', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing service canada', '1')
INSERT INTO serp VALUES('cheap essay', 'cheap essay writing 24', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay online', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay cheap', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay uk', '1')
INSERT INTO serp VALUES('buy essay', 'buy essay papers', '1')
...
将结果转储为 JSON
通用结果格式:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.suggests = [];
FOREACH item IN p1.results;
obj.suggests.push(item.suggest);
END;
obj.json %]
起始文本:
[
结束文本:
]
结果示例:
[{"suggests":["buy essay online","buy essay cheap","buy essay uk","buy essays online no plagiarism","buy essay papers","buy essay online reviews","buy essays reddit","buy essay friend"],"totalcount":8}]
要使“Prepend text”和“Append text”选项在任务编辑器中可用,需要激活“More options”。
结果处理
A-Parser 允许在数据抓取过程中直接处理结果,在本节中,我们列出了 SE::Google::Suggest 爬虫工具最常用的案例。
深度抓取选项 (Parse to level)
该选项指示爬虫工具将获取的结果按深度代入查询队列,直到指定的级别,例如:
- 如果指定为第 1 级,则爬虫工具会将从原始查询中获得的所有结果添加到查询中
- 如果指定为第 2 级,则爬虫工具会将从原始查询中获得的所有结果 + 从第 1 级查询中获得的所有结果添加到查询中
- 依此类推
简单来说,这就是将获取的结果代入查询队列,从而可以抓取更多结果。 由于结果中很可能会有重复项,为了让爬虫工具不做多余的工作(不抓取相同的内容),建议开启 查询去重 (Unique queries)
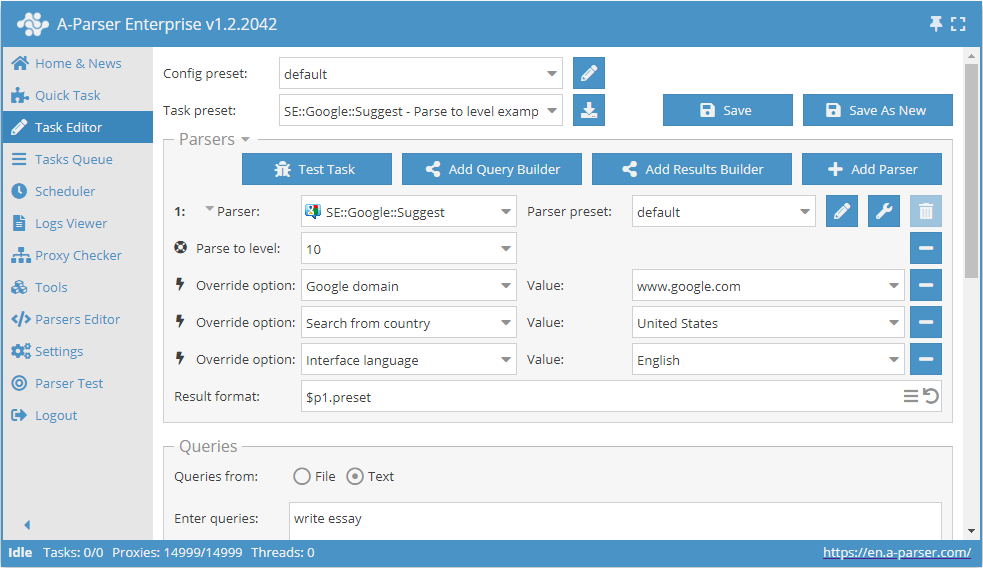
下载示例
eJx9VE1v2zAM/SsGkcMGZEF72MW3NFiGDlmd1c0pyEGIaVerLHmSnDQw/N9HKo7t
bEFvpvj4+PFIN+CFe3Nriw69g3jbQBW+IYb0Wxx/N6ZQGMdpXRTofPQlWgvrMPIm
UnhAFeG7KCuFMIWKHZY5trdCCZFhLmpFXw34U4WUwlReGu3IJzMyA8WKeenlIFRN
mPu7doQ/oLUyw0tAZkoh9QCG4/E4K0Li2d6U8EFoMcoBm/Qj6OsYihra3W4KNCXq
xS2NLQVPa1Ldz7rR9c5UHPDFkDOXYUSXGLKeRMlsk0x4ZO8sD0SfPs/8OzOILJM8
G6HOGXiuQ9aNln9CNc5bqQvCk2kluqWlrmPwGEj48XSpcAuTYAPR1CH+1zkGYm9r
nIKjapeCasl6Ry6UI4/0aIU3Nunkihsweq5UkGqABfqHWqqM9mCeU9BjF3gbkvzH
0fYdjlORHEdLNfQswXpIfg5RmVmZghrXhtpWspSebLcwtWZt7ujxDbHqx/bEsNJY
7NN0zF12uocKNWs/qDavhqerNq6UuX7cG53LIun26YKs9QsdXaIXhk+H+9K1UqSK
w+dhQ+auk4GNocB/gxchBd/C5brAG6Pcj/RcamUlbeBXLrCkSY6zdpR7odTmeTX2
wLBRfFQ87gidEydguMfC0B5RM+2uv/v+F9LcvP64aUmm3259RnNPjKU3Go4jDejS
27/f2JZm
结果过滤(使用否定词)
使用否定词可以立即剔除您不需要的结果。 同样,使用过滤器也可以仅保留包含所需单词的结果。
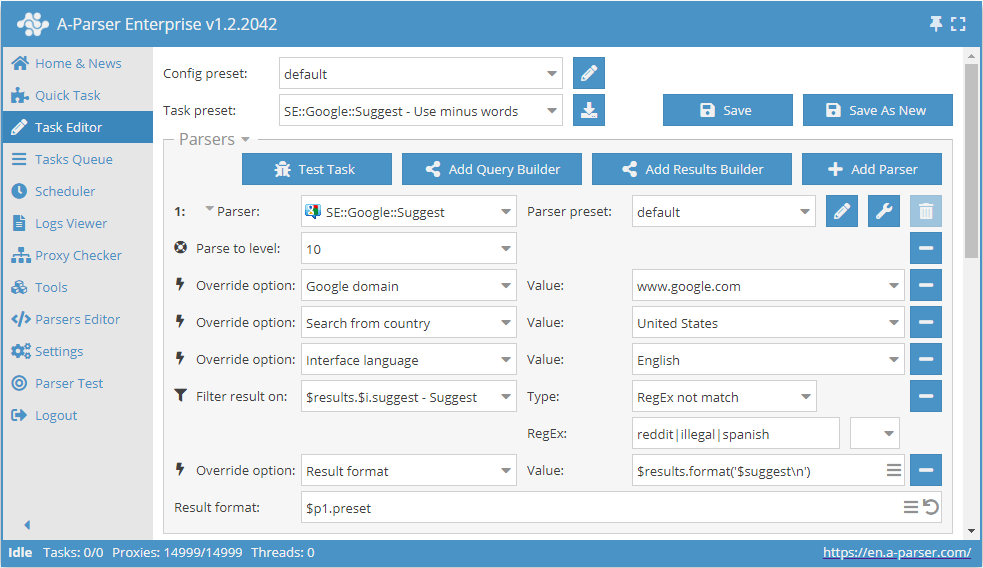
下载示例
eJx9VE1vGjEQ/SvIQkojpSgcetkbQaFqRUMa4EQ4WOywceO1tx4vFBH+e2e83g9a
xG1n5r2ZNx/ro/AS3/HZAYJHkayOogjfIhHzxyT5am2mIUnmZZYB+t7n3hKhlytT
Ym9vXYriThTSITgmry5xCJHCVpaavo7CHwqg3Lbwyhpmq5TMkGIKO9Dk2UldEmZ4
f+rgd+CcSqEmpDaXyrRgsd/vB1koPNjYXFyhZp0aYjm/Bn3rQsF0oVulPTgK07S4
tWQVv7gnjJ2v7yJuUZEcGOtz6TdvnbwO0lT5D6U1ZFJ/YCGNQgZUMyLENYlb6yhh
FNEm7Ucxgyr+6aYfNb2+mptbcVqva+U4CQjmFMNBXH4TnMsdLGzVL7TuCVlPMg+V
UumBo3Wp24H/wxkkt0UNSF1V4ANpqy6N+h2UonfKZIQn0ynAiaP1JcJDSMLOQ61w
JfrB5rmWgf+z4ojEuxJo7qR2IklL2gS2UiNFFC1Beutm8e6So7BmpHW4uRYW0j+U
Sqd00KMtkb5F4mXI7L8cp6bDbila2t6RhlpoMB5mP1pSaqc2o76Npa61ypUnG8e2
NLyae3K+AxTN1J4YllsHTZUoLxanH7oAwwfSLm1UtK6zLs4Wc+7cWLNV2SweXY0s
zYJejZkZ27zQwG2ZUmtaCsJLeyAjjFtgoxX4L3kcSvA/Xb8Swlur8fu8klo4RQf4
hQXmNMhu1ZhyI7Vevky7EdEeFD8OPO4eIMqDYLiHzNIZUTOndfN+NW/g8eIrlhxP
tKZf+FyhuSfGko+Gg+FHHZ7+As4s2Yc=
另请参阅:结果过滤器
可用设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Client | Chrome omnibox | 选择来源,用于收集建议 (Search page / Chrome omnibox) |
| Follow suggests | Human | 选择在使用 Parser to level 时需要代入查询的建议类型 (All / Synthetic / Human) |
| Google domain | www.google.com | 选择域名 |
| Search from country | Global | 选择进行搜索的国家 |
| Interface language | English | 选择界面语言 |
| Remove HTML tags | ☑ | 删除 HTML 标签 |